Introduction
This technical guide documents the Scout architecture and describes important concepts used in Scout.
|
This document is referring to a past Scout release. Please click here for the recent version. Looking for something else? Visit https://eclipsescout.github.io for all Scout related documentation. |
|
This document is not complete. Contributions are welcome! If you like to help, please create a pull request. Thanks! Repository: https://github.com/bsi-software/org.eclipse.scout.docs |
1. Overview
Scout is a framework for creating modern business applications. Such applications are typically separated into multiple tiers where each tier is responsible for a specific part of the application like presenting information to the user or processing business logic and persisting data. Scout solves these requirements by providing a separation of such tiers out of the box.
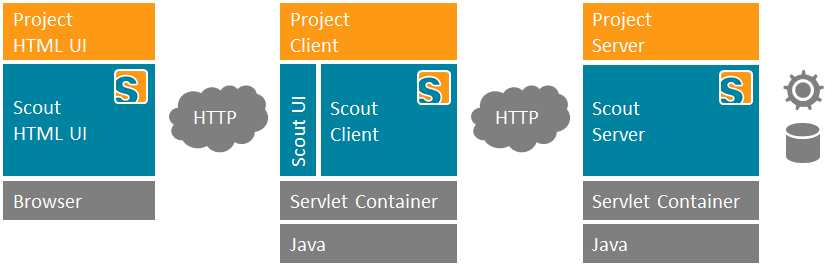
A typical Scout application consists of the following parts:
-
A server layer responsible for persisting data on a database and possibly providing and consuming webservices. The scout server layer provides utilities to simplify the most common tasks.
-
A client layer responsible for handling the Java UI code. It consists of a model represented by plain Java classes as well as services and utilities to implement behaviour associated with client code. The scout client layer provides utilities to simplify the most common tasks. For simplicity, the client model is processed in a single threaded way to avoid synchronization. Callbacks, e.g. for validating a field or calling services when opening a form run inside a model job.
-
A UI layer responsible for rendering the client model in the browser. Since the scout UI layer already provides JavaScript/HTML/CSS code for many common UIs, the project specific code in this layer is typically quite small. Examples are specific CSS styling or a new custom input field for special purposes.
Server and client both run in a servlet container, such as Apache Tomcat. They are usually deployed as separate war files in order to be able to scale them differently. However, it is also possible to create a single war file.
2. Scout Platform
Scout contains a platform which provides basic functionality required by many software applications. The following list gives some examples for which tasks the platform is responsible for:
2.1. Application Lifecycle
The lifecycle of a Scout application is controlled by implementations of org.eclipse.scout.rt.platform.IPlatform.
This interface contains methods to start and stop the application and to retrieve the Bean Manager associated with this application.
The class org.eclipse.scout.rt.platform.Platform provides access to the current platform instance. On first access the platform is automatically created and started.
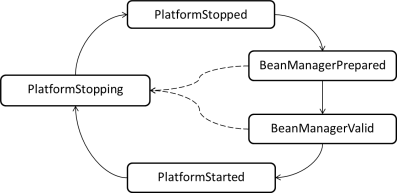
During its startup, the platform transitions through several states. Depending on the state of the platform some components may already be initialized and ready to use while others are not available yet.
See enum org.eclipse.scout.rt.platform.IPlatform.State for a description of each state and what may be used in a certain state.
2.1.1. Platform Listener
To participate in the application startup or shutdown a platform listener can be created.
For this a class implementing org.eclipse.scout.rt.platform.IPlatformListener must be created. The listener is automatically a bean and must therefore not be registered anywhere.
See Section 2.3 to learn more about bean management in Scout and how the listener becomes a bean.
As soon as the state of the platform changes the listener will be notified.
public class MyListener implements IPlatformListener {
@Override
public void stateChanged(PlatformEvent event) {
if (event.getState() == State.PlatformStarted) {
// do some work as soon as the platform has been started completely
}
}
}| As platform listeners may run as part of the startup or shutdown not the full Scout platform may be available. Depending on the state some tasks cannot be performed or some platform models are not available yet! |
2.2. Class Inventory
Scout applications use an inventory containing the classes available together with some meta data about them. This allows finding classes available on the classpath by certain criteria:
-
All subclasses of a certain base class (also known as type hierarchy)
-
All classes having a specific annotation.
This class inventory can be accessed as described in listing Listing 2.
IClassInventory classInventory = ClassInventory.get();
// get all classes below IService
Set<IClassInfo> services = classInventory.getAllKnownSubClasses(IService.class);
// get all classes having a Bean annotation (directly on them self).
Set<IClassInfo> classesHavingBeanAnnot = classInventory.getKnownAnnotatedTypes(Bean.class);2.2.1. scout.xml
In its static initializer, the ClassInventory collects classes in projects containing a resource called META-INF/scout.xml.
Scanning all classes would be unnecessarily slow and consume too much memory.
The file scout.xml is just an empty xml file. Scout itself also includes scout.xml files in all its projects.
The format XML was chosen to allow adding exclusions in large projects, but this feature is not implemented right now.
It is recommended to add an emtpy scout.xml file into the META-INF folder of your projects, such that the classes are available in the 'ClassInventory'.
|
Scout uses Jandex [1] to build the class inventory. The meta data to find classes can be pre-computed during build time into an index file describing the contents of the jar file. See the jandex project for details.
2.3. Bean Manager
The Scout bean manager is a dynamic registry for beans. Beans are normal Java classes usually having some meta data describing the characteristics of the class.
The bean manager can be changed at any time. This means beans can be registered or unregistered while the application is running. For this the bean manager contains methods to register and unregister beans. Furthermore methods to retrieve beans are provided.
The next sections describe how beans are registered, the different meta data of beans, how instances are created, how they can be retrieved and finally how the bean decoration works.
2.3.1. Bean registration
Usually beans are registered during application startup. The application startup can be intercepted using platform listeners as described in Section 2.1.1.
public class RegisterBeansListener implements IPlatformListener {
@Override
public void stateChanged(PlatformEvent event) {
if (event.getState() == State.BeanManagerPrepared) {
// register the class directly
BEANS.getBeanManager().registerClass(BeanSingletonClass.class);
// Or register with meta information
BeanMetaData beanData = new BeanMetaData(BeanClass.class).withApplicationScoped(true);
BEANS.getBeanManager().registerBean(beanData);
}
}
}There is also a predefined bean registration built into the Scout runtime. This automatically registers all classes having an org.eclipse.scout.rt.platform.@Bean annotation. Therefore it is usually sufficient to only annotate a class with @Bean to have it available in the bean manager as shown in listing Listing 4.
@Bean
public class BeanClass {
}
As the @Bean annotation is an java.lang.annotation.@Inherited annotation, this automatically registers all child classes too. This means that also interfaces may be @Bean annotated making all implementations automatically available in the bean manager! Furthermore other annotations may be @Bean annotated making all classes holding these annotations automatically to beans as well.
|
If you inherit a @Bean annotation from one of you super types but don’t want to be automatically registered into the bean manger you can use the org.eclipse.scout.rt.platform.@IgnoreBean annotation. Those classes will then be skipped.
|
@TunnelToServer
There is a built in annotation org.eclipse.scout.rt.shared.@TunnelToServer. Interfaces marked with this annotation are called on the server. The server itself ignores this annotation.
To achieve this a bean is registered on client side for each of those interfaces. Because the platform cannot directly create an instance for these beans a specific producer is registered which creates a proxy that delegates the call to the server. Please note that this annotation is not inherited. Therefore if an interface extends a tunnel-to-server interface and the new methods of this interface should be called on the server as well the new child interface has to repeat the annotation!
The proxy is created only once for a specific interface bean.
2.3.2. Bean Scopes
The most important meta data of a bean is the scope. It describes how many instances of a bean can exist in a single application. There are two different possibilities:
-
Unlimited instances: Each bean retrieval results in a new instance of the bean. This is the default.
-
Only one instance: There can only be one instance by Scout platform. From an application point of view this can be seen as singleton. The instance is created on first use and each subsequent retrieval of the bean results in this same cached instance.
As like all bean meta data this characteristic can be provided in two different ways:
@ApplicationScoped
public class BeanSingletonClass {
}So the Java annotation org.eclipse.scout.rt.platform.@ApplicationScoped describes a bean having singleton characteristics.
Also @ApplicationScoped is an @Inherited annotation. Therefore all child classes automatically inherit this characteristic like with the @Bean annotation.
|
2.3.3. Bean Creation
It is not only possible to influence the number of instances to be created (see Section 2.3.2), but also to create beans eagerly, execute methods after creation (like constructors) or to delegate the bean creation completely. These topics are described in the next sections.
Eager Beans
By default beans are created on each request. An exception are the beans marked to be application scoped (as shown in Section 2.3.2). Those beans are only created on first request (lazy). This means if a bean is never requested while the application is running, there will never be an instance of this class.
But sometimes it is necessary to create beans already at the application startup (eager). This can be done by marking the bean as org.eclipse.scout.rt.platform.@CreateImmediately. All classes holding this annotation must also be marked as @ApplicationScoped! These beans will then be created as part of the application startup.
Constructors
Beans must have empty constructors so that the bean manager can create instances. But furthermore it is possible to mark methods with the javax.annotation.@PostConstruct annotation. Those methods must have no parameters and will be called after instances have been created.
| When querying the bean manager for an application scoped bean, it will always return the same instance. However, the constructor of an application scoped bean may run more than once, whereas a method annotated with @PostConstruct in an application scoped been is guaranteed to run exactly once. |
2.3.4. Bean Retrieval
To retrieve a bean the class org.eclipse.scout.rt.platform.BEANS should be used. This class provides (amongst others) the following methods:
BeanSingletonClass bean = BEANS.get(BeanSingletonClass.class);
BeanClass beanOrNull = BEANS.opt(BeanClass.class);-
The
get()method throws an exception if there is not a single bean result. So if no bean can be found or if multiple equivalent bean candidates are available this method fails! -
The
opt()method requires a single or no bean result. It fails if multiple equivalent bean candidates are available and returnsnullif no one can be found. -
The
all()method returns all beans in the correct order. The list may also contain no beans at all.
There are now two more annotations that have an effect on which beans are returned if multiple beans match a certain class. Consider the following example bean hierarchy:
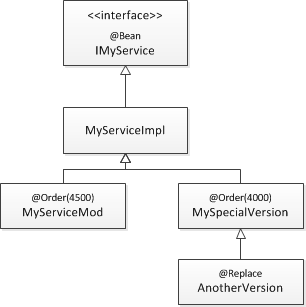
In this situation 4 bean candidates are available: MyServiceImpl, MyServiceMod, MySpecialVersion and AnotherVersion.
But which one is returned by BEANS.get(IMyService.class)? Or by BEANS.get(MySpecialVersion.class)?
This can be influenced with the org.eclipse.scout.rt.platform.@Order and org.eclipse.scout.rt.platform.@Replace annotations.
The next sections describe the idea behind these annotations and gives some examples.
@Order
This annotation works exactly the same as in the Scout user interface where it brings classes into an order. It allows to assign a double value to a class. All beans of a certain type are sorted according to this value in ascending order. This means a low order value is equivalent with a low position in a list (come first).
Please note that the @Order annotation is not inherited so that each bean must declare its own value where it fits in.
The @Order annotation value may be inherited in case it replaces. See the next section for details.
|
If a bean does not declare an order value, the default of 5000 is used. Scout itself uses orders from 4001 to 5999.
So for user applications the value 4000 and below can be used to declare more important beans.
For testing bean mocks the value -10'000 can be used which then usually comes before each normal Scout or application bean.
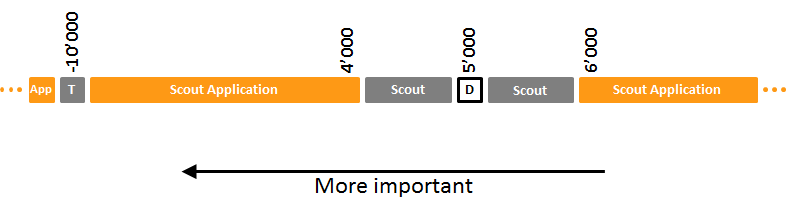
@Replace
The @Replace annotation can be set to beans having another bean as super class. This means that the original bean (the super class) is no longer available in the Scout bean manager and only the new child class is returned.
If the replacing bean (the child class) has no own @Order annotation defined but the replaced bean (the super class) has an @Order value, this order is inherited to the child. This is the only special case in which the @Order annotation value is inherited!
2.3.5. Examples
The next examples use the bean situation as shown in figure Figure 1. In this situation the bean manager actually contains 3 beans:
-
AnotherVersionwith@Orderof 4000. This bean has no own order and would therefore get the default order of 5000. But because it is replacing another bean it inherits its order. -
MyServiceModwith@Orderof 4500. This bean declares its own order. -
MyServiceImplwith@Orderof 5000. This bean gets the default order of 5000 because it does not declare an order.
The bean MySpecialVersion is not part of the bean manager because it has been replaced by AnotherVersion.
-
BEANS.get(IMyService.class): ReturnsAnotherVersioninstance. The result cannot be an exact match because the requested type is an interface. Therefore of all candidates there is one single candidate with lowest order (comes first). -
BEANS.get(MyServiceImpl.class): ReturnsMyServiceImplbecause there is an exact match available. -
BEANS.get(MySpecialVersion.class): ReturnsAnotherVersion. The result cannot be an exact match because there is no exact bean with this class in the bean manager (MySpecialVersionhas been replaced). Therefore onlyAnotherVersionremains as candidate in the hierarchy belowMySpecialVersion. -
BEANS.get(MyServiceMod.class): ReturnsMyServiceModbecause there is no other candidate. -
BEANS.all(IMyService.class): Returns a list with all beans sorted by@Order. This results in:AnotherVersion,MyServiceMod,MyServiceImpl.
If MyServiceMod would have no @Order annotation, there would be two bean candidates available with the same default order of 5000: MyServiceImpl and MyServiceMod. In this case a call to BEANS.get(IMyService.class) would fail because there are several equivalent candidates. Equivalent candidates means they have the same @Order value and the system cannot decide which one is the right one.
|
2.3.6. Bean Decoration
Bean decorations allow to wrap interfaces with a proxy to intercept each method call to the interface of a bean and apply some custom logic.
For this a IBeanDecorationFactory has to be implemented. This is one single factory instance for the entire application. It decides which decorators are created for a bean request.
The factory is asked for decorators on every bean retrieval. This allows to write bean decoration factories depending on dynamic conditions.
As bean decoration factories are beans themselves, it is sufficient to create an implementation of org.eclipse.scout.rt.platform.IBeanDecorationFactory and to ensure this implementation is used (see Section 2.3.4).
This factory receives the bean to be decorated and the originally requested bean class to decide which decorators it should create.
In case no decoration is required the factory may return null. Then the original bean is used without decorations.
Decorations are only supported if the class obtained by the bean manager (e.g. by using BEANS.get()) is an interface!
|
It is best practice to mark all annotations that are interpreted in the bean decoration factory with the annotation org.eclipse.scout.rt.platform.@BeanInvocationHint. However this annotation has no effect at runtime and is only for documentation reasons.
|
The sample in listing Listing 7 wraps each call to the server with a profiler decorator that measures how long a server call takes.
@Replace
public class ProfilerDecorationFactory extends SimpleBeanDecorationFactory {
@Override
public <T> IBeanDecorator<T> decorate(IBean<T> bean, Class<? extends T> queryType) {
return new BackendCallProfilerDecorator<>(super.decorate(bean, queryType));
}
}
public class BackendCallProfilerDecorator<T> implements IBeanDecorator<T> {
private final IBeanDecorator<T> m_inner;
public BackendCallProfilerDecorator(IBeanDecorator<T> inner) {
m_inner = inner;
}
@Override
public Object invoke(IBeanInvocationContext<T> context) {
final String className;
if (context.getTargetObject() == null) {
className = context.getTargetMethod().getDeclaringClass().getSimpleName();
}
else {
className = context.getTargetObject().getClass().getSimpleName();
}
String timerName = className + '.' + context.getTargetMethod().getName();
TuningUtility.startTimer();
try {
if (m_inner != null) {
// delegate to the next decorator in the chain
return m_inner.invoke(context);
}
// forward to real bean
return context.proceed();
}
finally {
TuningUtility.stopTimer(timerName);
}
}
}2.3.7. Destroy Beans
Application scoped beans can declare methods annotated with javax.annotation.@PreDestroy. These methods will be called when the Scout platform is stopping.
The methods may have any visibility modifier but must not be static and must not declare any parameters.
If such a pre-destroy method throws an exception, the platform will continue to call all other pre-destroy methods (even methods on the same bean).
Please note that pre-destroy methods are only called for application-scoped beans that already have created their instance.
Pre-destroy methods inherited from super classes are always called after the ones from the class itself. Methods that are overridden are only called on the leaf class. Private methods are always called (because they cannot be overridden). The order in which multiple methods in the same declaring class are called is undefined.
2.4. Configuration Management
Applications usually require some kind of configuration mechanism to use the same binaries in a different environment or situation. Scout applications provide a configuration mechanism using properties files [2].
For each property a class cares about default values and value validation. These classes share the org.eclipse.scout.rt.platform.config.IConfigProperty interface and are normal application scoped beans providing access to a specific configuration value as shown in listing Listing 8. If the property class is an inner class it has to be defined as a static class with the static modifier.
import org.eclipse.scout.rt.platform.config.AbstractLongConfigProperty;
/**
* Property of data type {@link Long} with key 'my.custom.timeout' and default value '3600L'.
*/
public class MyCustomTimeoutProperty extends AbstractLongConfigProperty {
@Override
public String getKey() {
return "my.custom.timeout"; (1)
}
@Override
public String description() {
return "Description of the custom timeout property. The default value is 3600.";
}
@Override
public Long getDefaultValue() {
return 3600L; (2)
}
}| 1 | key |
| 2 | default value |
To read the configured value you can use the CONFIG class as demonstrated in Listing 9.
Long value = CONFIG.getPropertyValue(MyCustomTimeoutProperty.class);2.4.1. Property resolution
The given property key is searched in the following environments:
-
In the system properties (
java.lang.System.getProperty(String)). -
In the environment variables of the system (
java.lang.System.getenv(String)). -
In the properties file. The properties file can be
-
a file on the local filesystem where the system property with key
config.propertiesholds an absolute URL to the file or -
a file on the classpath with path
/config.properties(recommended).
-
-
If none of the above is found, the default value of the property is applied.
Supported formats are simple key-value pairs, list values and map values. For more details about the format please refer to the JavaDoc of the org.eclipse.scout.rt.platform.config.PropertiesHelper class.
Since the environment variable names are more restrictive in many shells and systems than the property names in Java, overriding a property containing a dot/period (.) with an environment variable would not be possible.
To still allow overriding of such properties, the following lookup rules are applied in-order to find a matching environment variable:
-
An exact match of your property key (
my.property) -
A match where periods are replaced by underscores (
my_property) -
An uppercase match of your property key (
MY.PROPERTY) -
An uppercase match where periods are replaced by underscores (
MY_PROPERTY)
When it comes to working with mapped config properties (subclasses of org.eclipse.scout.rt.platform.config.AbstractMapConfigProperty), there’s also some special mechanic to consider in terms of providing or overriding property map values using environment variables.
Since it is not possible to reliably retrieve the original map key from an environment variable (again, due to the restrictions mentioned above), property map values may be supplied using environment variables whose value is a JSON object string:
my_map_property={"map-key-01": "value-01", "map-key-02": "value-02", "map-key-03": null}The following rules apply, when such environment variables are read: * property map key/value pairs are added from the JSON object to the property map, overriding keys already being defined by sources of lower precedence (e.g. config.properties file) * a JSON object attribute value of "null" will remove a key potentially being defined by sources of lower precedence
The parsing of JSON object strings is abstracted away using the new org.eclipse.scout.rt.platform.config.IJsonPropertyReader interface as parsing JSON strings is not implemented in the platform itself.
However, there is a default implementation of this interface available in org.eclipse.scout.rt.dataobject which uses the org.eclipse.scout.rt.platform.dataobject.IDataObjectMapper feature to deserialize the JSON string into a Java Map.
In order to use this, an implementation of the IDataObjectMapper interface is also required (e.g. org.eclipse.scout.rt.jackson.dataobject.JacksonDataObjectMapper).
So in case you want to use this feature, you have to define
* org.eclipse.scout.rt:org.eclipse.scout.rt.dataobject
* org.eclipse.scout.rt:org.eclipse.scout.rt.jackson
as new dependencies of your application aggregator module (if they are not already present).
A properties file may import other config files from the classpath or any other absolute URL. This is done using the special key import. It can be a single value or a list:
-
import[0]=classpath:myConfigs/other.properties -
import[1]=file:/C:/path/to/my/settings.properties -
import[2]=file:${catalina.base}/conf/db_connection.properties
Scout already has some config properties. For a list and the corresponding documentation see Section 2.5.
2.4.2. Additional examples
Because the property classes are managed by the bean manager, you can use all the mechanisms to change the behavior (@Replace in particular).
Listing 10 demonstrates how you can use the replace annotation to change the existing ApplicationNameProperty class.
The value is no longer fetched via the config mechanism, because the getValue(String) method is overridden.
In this case a fixed value is returned.
import org.eclipse.scout.rt.platform.IgnoreBean;
import org.eclipse.scout.rt.platform.Replace;
import org.eclipse.scout.rt.platform.config.PlatformConfigProperties.ApplicationNameProperty;
@Replace
public class ApplicationNameConstant extends ApplicationNameProperty {
@Override
protected String readFromSource(String namespace) {
return "Contacts Application";
}
}The next example presented in Listing 11 uses the same idea.
In this case, the getKey() method is overridden to read the value from an other key as demonstrated is the Listing 12.
import org.eclipse.scout.rt.platform.IgnoreBean;
import org.eclipse.scout.rt.platform.Replace;
import org.eclipse.scout.rt.platform.config.PlatformConfigProperties.ApplicationNameProperty;
@Replace
public class ApplicationNamePropertyRedirection extends ApplicationNameProperty {
@Override
public String getKey() {
return "myproject.applicationName";
}
}### Redirected Application Config
myproject.applicationName=My Project Application2.4.3. Configuration validation
During the Platform startup all classes implementing the interface org.eclipse.scout.rt.platform.config.IConfigurationValidator are asked to validate configuration provided in the config.properties files.
If there is at least one IConfigurationValidator that accepts a given key-value-pair the configuration is considered to be valid. Otherwise the platform will not start.
The concrete implementation org.eclipse.scout.rt.platform.config.ConfigPropertyValidator will also check if a configured value matches the default value. In case it does an info message (warn in development mode) will be logged but the platform will still start.
To minimize configuration files such entries should be removed from config.properties files.
2.5. Scout Config Properties
| Key | Description | Data Type | Kind |
|---|---|---|---|
|
The display name of the application. Used e.g. in the info form and the diagnostic views. The default value is |
String |
Config Property |
|
The application version as displayed to the user. Used e.g. in the info form and the diagnostic views. The default value is |
String |
Config Property |
|
Specifies if the |
Boolean |
Config Property |
|
Specifies if the |
Boolean |
Config Property |
|
If the A positive value indicates that the cookie will expire after that many seconds have passed. A negative value means that the cookie is not stored persistently and will be deleted when the Web browser exits. A zero value causes the cookie to be deleted. The default value is 10 hours. |
Long |
Config Property |
|
If the The name must conform to RFC 2109. However, vendors may provide a configuration option that allows cookie names conforming to the original Netscape Cookie Specification to be accepted. By default |
String |
Config Property |
|
Specifies if the UI server should ensure a secure cookie configuration of the webapp. If enabled the application validates that the This property should be disabled if no secure connection (https) is used to the client browser (not recommended). The default value is true. |
Boolean |
Config Property |
|
Specifies the known credentials (username & passwords) of the Credentials are separated by semicolon. Username and password information are separated by colon. Usernames are case-insensitive and it is recommended that they should only consist of ASCII characters. Plain text passwords are case-sensitive. By default the password information consists of Base64 encoded salt followed by a dot followed by the Base64 encoded SHA-512 hash of the password (using UTF-16). Example: username1:base64EncodedSalt.base64EncodedPasswordHash;username2:base64EncodedSalt.base64EncodedPasswordHash To create a salt and hash tuples based on a clear text password use the If |
String |
Config Property |
|
Specifies if the passwords specified in property |
Boolean |
Config Property |
|
Specifies the Base64 encoded private key for signing requests from the UI server to the backend server. By validating the signature the server can ensure the request is trustworthy. Furthermore the CookieAccessController uses this private key to sign the cookie. New public-private-key-pairs can be created by invoking the class |
Base64 encoded String |
Config Property |
|
Specifies the Base64 encoded public key used to validate signed requests on the backend server. The public key must match the private key stored in the property New public-private-key-pairs can be created by invoking the class |
Base64 encoded String |
Config Property |
|
Number of milliseconds a signature on a request from the UI server to the backend server is valid (TTL for the authentication token). If a request is not received within this time, it is rejected. By default this property is set to 10 minutes. |
Long >= 0 |
Config Property |
|
The URL of the scout backend server (without any servlets). E.g.: http://localhost:8080 By default this property is null. |
String |
Config Property |
|
Specifies the maximal time (in seconds) to wait until running jobs are cancelled on session shutdown. Should be smaller than The default value is 10 seconds. |
Long >= 0 |
Config Property |
|
Specifies how long the client keeps fetched data before it is discarded. One of |
String |
Config Property |
|
Technical subject under which received client notifications are executed. By default |
Subject name as String |
Config Property |
|
Testing client session expiration in milliseconds. The default value is 1 day. |
Long >= 0 |
Config Property |
|
User data area (e.g. in the user home) to store user preferences. If nothing is specified the user home of the operating system is used. By default no user home is set. |
String |
Config Property |
|
The maximum number of client notifications that are consumed at once. The default is 30. |
Integer >= 0 |
Config Property |
|
The maximum amount of time in millisecons a consumer blocks while waiting for new notifications. The default is 10 seconds. |
Integer >= 0 |
Config Property |
|
Capacity of the client notification queue. If maximum capacity is reached, notification messages are dropped. The default value is 200. |
Integer >= 0 |
Config Property |
|
If no message is consumed for the specified number of milliseconds, client notification queues (with possibly pending notifications) are removed. This avoids overflows and unnecessary memory consumption. Old queues may exist if a node does not properly unregister (e.g. due to a crash). The default value is 10 minutes. |
Integer >= 0 |
Config Property |
|
Technical subject under which received cluster sync notifications are executed. The default value is |
String |
Config Property |
|
Specifies if the Scout platform should create proxy beans for interfaces annotated with By default this property is enabled if the property |
Boolean |
Config Property |
|
Configures individual Content Security Policy (CSP) directives. See https://www.w3.org/TR/CSP2/ and the Bean The value must be provided as a Map. Example: scout.cspDirective[img-src]= |
Map |
Config Property |
|
Enable or disable Content Security Policy (CSP) headers. The headers can be modified by replacing the bean |
Boolean |
Config Property |
|
Property to specify if the application is running in development mode. Default is false. |
Boolean |
Config Property |
|
Absolute URL to the deployed http(s):// base of the web-application. The URL should include proxies, redirects, etc. Example: https://www.my-company.com/my-scout-application/. This URL is used to replace |
String |
Config Property |
|
Comma separated list of URLs the By default no URLs are set. |
List |
Config Property |
|
Specifies the maximum life time in milliseconds for kept alive connections of the Apache HTTP client. The defautl value is 1 hour. |
Integer |
Config Property |
|
Configure the proxy ignore list for the ConfigurableProxySelector. If an URI matches the pattern no proxy connection is used. By default no proxy is configured. Example: scout.http.ignoreProxyPatterns[0]=https?://localhost(?::\d+)?(?:/.*)? scout.http.ignoreProxyPatterns[1]=… |
List |
Config Property |
|
Enable/disable HTTP keep-alive connections. The default value is defined by the system property |
Boolean |
Config Property |
|
Configuration property to define the default maximum connections per route of the Apache HTTP client. The default value is 32. |
Integer |
Config Property |
|
Specifies the total maximum connections of the Apache HTTP client. The default value is 128. |
Integer |
Config Property |
|
Configure proxies for the By default no proxy is used. The property value is of the format REGEXP_FOR_URI=PROXY_HOST:PROXY_PORT Example: scout.http.proxyPatterns[0]=.*\.example.com(:\d+)?=127.0.0.1:8888 scout.http.proxyPatterns[1]=.*\.example.org(:\d+)?=proxy.company.com |
List |
Config Property |
|
Fully qualified class name of the HTTP transport factory the application uses. The class must implement By default |
Fully qualified class name. The class must have |
Config Property |
|
Specifies if Jandex indexes should be rebuilt. Is only necessary to enable during development when the class files change often. The default value is false. |
Boolean |
Config Property |
|
Connect timeout in milliseconds to abort a webservice request, if establishment of the connection takes longer than this timeout. A timeout of null means an infinite timeout. The default value is null. |
Integer >= 0 |
Config Property |
|
Number of ports to be preemptively cached to speed up webservice calls. The default value is 10. |
Integer >= 0 |
Config Property |
|
Indicates whether to use a preemptive port cache for webservice clients. Depending on the implementor used, cached ports may increase performance, because port creation is an expensive operation due to WSDL and schema validation. The cache is based on a The default value is true. |
Boolean |
Config Property |
|
Maximum time in seconds to retain ports in the cache if the value of |
Long >= 0 |
Config Property |
|
To indicate whether to pool webservice clients. Creating new service and Port instances is expensive due to WSDL and schema validation. Using the pool helps reducing these costs. The default value is true. The pool size is unlimited but its elements are removed after a certain time (configurable) If this value is true, the value of property |
Boolean |
Config Property |
|
Read timeout in milliseconds to abort a webservice request, if it takes longer than this timeout for data to be available for read. A timeout of null means an infinite timeout. The default value is null. |
Integer >= 0 |
Config Property |
|
Fully qualified class name of the JAX-WS implementor to use. The class must extend By default, JAX-WS Metro (not bundled with JRE) is used. For that to work, add the Maven dependency to JAX-WS Metro to your server application`s pom.xml: com.sun.xml.ws:jaxws-rt:2.2.10. |
Fully qualified class name. The class must have |
Config Property |
|
Fully qualified class name of the JAX-WS implementor to use. The class must extend By default, JAX-WS Metro (not bundled with JRE) is used. For that to work, add the Maven dependency to JAX-WS Metro to your server application`s pom.xml: com.sun.xml.ws:jaxws-rt:2.2.10. |
Fully qualified class name. The class must have |
Config Property |
|
Indicates whether to log SOAP messages in debug or info level. The default value is false. |
Boolean |
Config Property |
|
Security Realm used for Basic Authentication; used by |
String |
Config Property |
|
Technical Subject used to authenticate webservice requests. The default value is |
Subject name as String |
Config Property |
|
Technical subject used to invoke JAX-WS handlers if the request is not authenticated yet; used by The default value is |
Subject name as String |
Config Property |
|
Specifies whether threads of the core-pool should be terminated after being idle for longer than the value of property |
Boolean |
Config Property |
|
The number of threads to keep in the pool, even if they are idle. The default value is 25. |
Integer >= 0 |
Config Property |
|
The time limit (in seconds) for which threads, which are created upon exceeding the |
Long >= 0 |
Config Property |
|
The maximal number of threads to be created once the value of |
Integer >= 0 |
Config Property |
|
Specifies whether all threads of the core-pool should be started upon job manager startup, so that they are idle waiting for work. By default this is disabled in development mode (property |
Boolean |
Config Property |
|
Name of the topic for cluster notifications published by scout application. |
IDestination |
Config Property |
|
Name of the topic for cluster notifications published by scout application. |
IDestination |
Config Property |
|
Contains the configuration to connect to the network or broker. This configuration is specific to the MOM implementor Example to connect to a peer based cluster, which is useful in development mode because there is no central broker: scout.mom.cluster.environment[scout.mom.name]=Scout Cluster MOM scout.mom.cluster.environment[scout.mom.connectionfactory.name]=ClusterMom scout.mom.cluster.environment[java.naming.factory.initial]=org.apache.activemq.jndi.ActiveMQInitialContextFactory scout.mom.cluster.environment[java.naming.provider.url]=failover:(peer://mom/cluster?persistent=false) scout.mom.cluster.environment[connectionFactoryNames]=ClusterMom |
Map |
Config Property |
|
Specifies the MOM implementor. Example to work with a JMS based implementor: scout.mom.cluster.implementor=org.eclipse.scout.rt.mom.jms.JmsMomImplementor |
Fully qualified class name. The class must have |
Config Property |
|
Specifies the default Marshaller to use if no marshaller is specified for a MOM or a destination. By default the |
Fully qualified class name. The class must have |
Config Property |
|
Specifies the default topic to receive cancellation request for |
IDestination |
Config Property |
|
Specifies if |
Boolean |
Config Property |
|
Specifies the cluster node name. If not specified a default id is computed. |
String |
Config Property |
|
Time to live for level permission check caching in milliseconds. If calculating the permission level for a permission instance, it can be internally cached. This caching is typically useful in a client and should be relative small (few minutes). If no value is set, caching is disabled. As default, no time to live is set and therefore caching is disabled. |
Long >= 0 |
Config Property |
|
Absolute path to the root directory of the |
String |
Config Property |
|
Server sessions that have not been accessed for the specified number of milliseconds are removed from the cache. The default value is one day. |
Long >= 0 |
Config Property |
|
Specifies if the service tunnel should compress the data. If null, the response decides which is default to true. |
Boolean |
Config Property |
|
Specifies the default maximum connections per route property for the HTTP service tunnel. Overrides the value from Default value is 2048. |
Integer |
Config Property |
|
Specifies the default total maximum connections property for the HTTP service tunnel. Overrides the value from The default value is 2048. |
Integer |
Config Property |
|
Specifies the URL to the ServiceTunnelServlet on the backend server. By default this property points to the value of property |
String |
Config Property |
|
If specified all emails are sent to this address instead of the real one. This may be useful during development to not send emails to real users by accident. |
String |
Config Property |
|
Socket connection timeout value in milliseconds. |
Integer |
Config Property |
|
Socket read timeout value in milliseconds. |
Integer |
Config Property |
|
If true a direct JDBC connection is created. Otherwise a JNDI connection is used. The default value is true. |
Boolean |
Config Property |
|
The driver name to use. By default |
String |
Config Property |
|
The JDBC mapping name. By default |
String |
Config Property |
|
Connections will be closed after this timeout in milliseconds even if the connection is still busy. The default value is 6 hours. |
Long >= 0 |
Config Property |
|
Idle connections will be closed after this timeout in milliseconds. The default value is 5 minutes. |
Long >= 0 |
Config Property |
|
The maximum number of connections to create. The default pool size is 25. |
Integer >= 0 |
Config Property |
|
Semicolon separated list of properties to pass to the JDBC connection. The default value is null. E.g.: key1=val1;key2=val2 |
String |
Config Property |
|
Maximum number of cached SQL statements. The default value is 25. |
Integer >= 0 |
Config Property |
|
The name of the object to lookup in the JNDI context. Default is null. |
String |
Config Property |
|
The name of the object to lookup in the JNDI context. Default is null. |
String |
Config Property |
|
JNDI provider url (e.g. |
String |
Config Property |
|
A colon-separated list of package prefixes for the class name of the factory class that will create a URL context factory. Default is null. |
String |
Config Property |
|
The password to connect to the database (JDBC or JNDI) |
String |
Config Property |
|
Id of the transaction member on which the connection is available. |
String |
Config Property |
|
The username to connect to the database (JDBC or JNDI) |
String |
Config Property |
|
If this property is set to true, the This is useful for debug/testing purposes or exporting forms to JSON. By default this property is false. |
Boolean |
Config Property |
|
Maximum number of threads per server that can be created to load tiles. The default value is 25. |
Integer >= 0 |
Config Property |
|
Maximum number of seconds a tile load job can execute until it is automatically cancelled. The default value is 2 minutes. |
Integer >= 0 |
Config Property |
|
URIs to DER (Base64) encoded certificate files that should be trusted. The URI may refer to a local file or a resource on the classpath (use classpath: prefix). The default value is an empty list. |
List of Strings |
Config Property |
|
The polling request (which waits for a background job to complete) stays open until a background job has completed or the specified number of seconds elapsed. This property must have a value between 3 and the value of property By default this property is set to 1 minute. |
Long >= 0 |
Config Property |
|
Contains a comma separated list of supported locales (e.g. en,en-US,de-CH). This is only relevant if locales.json and texts.json should be sent to the client, which is not the case for remote apps. So this property is only used for JS only apps. By default no locales are supported. |
List |
Config Property |
|
If a user is inactive (no user action) for the specified number of seconds, the session is stopped and the user is logged out. By default this property is set to 4 hours. |
Long >= 0 |
Config Property |
|
The maximal timeout in seconds to wait for model jobs to complete during a UI request. After that timeout the model jobs will be aborted so that the request may return to the client. By default this property is set to 1 hour. |
Long >= 0 |
Config Property |
|
When this property returns true, file pre-building is performed when the UI application server starts up. This means the application start takes more time, but in return the first user request takes less time.
These files are typically processed by Scout`s By default this property is enabled when the application is not running in development mode (property |
Boolean |
Config Property |
|
Contains a comma separated list of files in Since it takes a while to build files, especially JS and CSS (LESS) files, we want to do this when the server starts. Otherwise its always the first user who must wait a long time until all files are built. Since CSS and JS files are always referenced by a HTML file, we simply specify the main HTML files in this property. By default no files are prebuild. This property only has an effect if property |
List |
Config Property |
|
Maximum time in second to wait for all client sessions to be stopped after the HTTP session has become invalid. After this number of seconds a By default this property is set to 1 minute. |
Integer >= 0 |
Config Property |
|
Maximum time in seconds to wait for the write lock when the session store is unbound from the HTTP session. This value should not be too large because waiting on the lock might suspend background processes of the application server. By default this property is set to 5 seconds. |
Integer >= 0 |
Config Property |
|
Number of seconds before the housekeeping job starts after a UI session has been unregistered from the store. By default this property is set to 20 seconds. |
Integer >= 0 |
Config Property |
|
Maximum time in seconds to wait for a client session to be stopped by the housekeeping job. The value should be smaller than the session timeout (typically defined in the web.xml) and greater than the value of property By default this property is set to 1 minute. |
Integer >= 0 |
Config Property |
|
The name of the UI theme which is activated when the application starts. |
String |
Config Property |
|
Enable or disable changing UrlHints using URL parameters in the browser address line. By default has the same value as the config property |
Boolean |
Config Property |
|
Specifies the default DefaultDecimalSupportProvider to use. By default the 'DefaultDecimalSupportProvider' is used. |
Fully qualified class name. The class must have |
Config Property |
|
Comma separated list of simple URI patterns for which the |
List of Strings |
Servlet Filter Config |
|
Root folder of the |
Absolute path to the root folder. |
Servlet Filter Config |
|
The minimum number of bytes in the response of a GET request so that compression is applied. A value of < 0 disables compression. Used in |
Integer |
Servlet Filter Config |
|
Regex (not case sensitive) of servlet request pathInfo that is compressed for GET requests. Used in |
String |
Servlet Filter Config |
|
The minimum number of bytes in the response of a POST request so that compression is applied. A value of < 0 disables compression. Used in |
Integer |
Servlet Filter Config |
|
Regex (not case sensitive) of servlet request pathInfo that is compressed for POST requests. Used in |
String |
Servlet Filter Config |
|
Path to resource within war file. Normally starting with /WEB-INF. Default is null. |
String |
Servlet Config |
3. Client Model
3.1. Desktop
3.1.1. Desktop Bench Layout
The Desktop Layout can be configured using the IDesktop.setBenchLayoutData method. This property is observed and might be changed during the applications lifecycle.
The desktop consists out of 9 view stacks (see Figure 2). Each form can be assigned to a single view stack using the property DisplayViewId (IForm.getConfiguredDisplayViewId).
If multiple forms are assigned to the same view stack the views will be displayed as tabs where the top form is visible and the corresponding tab selected.
| Tabs are only visible if the form does have a title, subtitle or an image. |
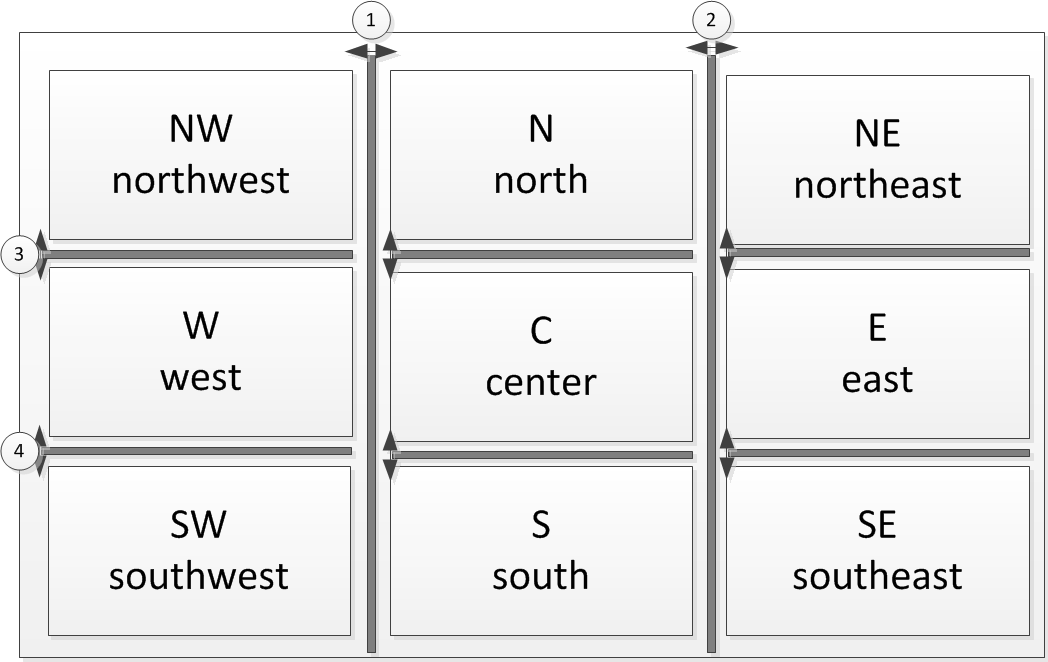
The east, center and west columns are separated with splitters which can be moved according to the layout data properties. Each column is split into a north, center and south part. Within a column the north, center and south parts can not differ in their width.
The modifications (splitter movements) are cached when a cache key (BenchLayoutData.withCacheKey) is set. In case the cache key is null the layout starts always with the initial values.
An example of a bench layout data configuration with a fixed north (N) view stack and an south (S) view stack with an minimal size. See org.eclipse.scout.rt.client.ui.desktop.bench.layout.FlexboxLayoutData API for the documentation of the properties.
desktop.setBenchLayoutData( (1)
new BenchLayoutData()
.withCacheKey("a-cache-key") (2)
.withCenter( (3)
new BenchColumnData()
.withNorth(new FlexboxLayoutData().withGrow(0).withShrink(0).withInitial(280).withRelative(false)) (4)
.withCenter(new FlexboxLayoutData()) (5)
.withSouth(new FlexboxLayoutData().withShrink(0).withInitial(-1)))); (6)| 1 | set the BenchLayoutData to the desktop. |
| 2 | set a cache key to store the layout modifications (dragging splitters) to the session store. Aware the settings are stored to the browsers session store they are not transfered over different browsers nor systems. |
| 3 | configure the center column (N, C, S). |
| 4 | The north part is fixed in size so the splitter between north (N) and center © view stack is disabled. The size is fixed to 280 pixel. |
| 5 | Use default for the center © view stack. |
| 6 | The south part is using the UI height as initial size and is growable but not shrinkable. |
3.2. Multiple Dimensions Support
Several components support multiple dimensions for visibility or enabled flags. This means the component is only visible or enabled if all dimensions are set to true. This gives developers the flexibility to e.g. use a dimension for granting and one for the business logic.
A total of 8 dimensions are available for a certain component type and attribute. This means you e.g. have a total of 8 dimensions for Form Field visibility in your application. And 8 dimensions for enabled-states of Actions. So the dimensions are not consumed by component instance but by component type. This means you have to be careful in defining new dimensions as all components of the same type share these dimensions.
| Some of these dimensions are already used internally. Refer to the implementation and JavaDoc of the component for details about how many dimensions are available for custom use. |
menu.setEnabled(false); (1)
menu.setEnabledGranted(false); (2)
menu.setVisible(false, IDimensions.VISIBLE_CUSTOM); (3)
formField.setVisible(true, false, true, "MyCustomDimension"); (4)
formField2.setVisible(true, true, true); (5)
formField3.isEnabled(IDimensions.ENABLED_CUSTOM); (6)
formField3.isEnabled(IDimensions.ENABLED); (7)
formField3.isEnabled(); (8)
formField3.isEnabledIncludingParents(); (9)| 1 | Disables the menu using the internal default dimension |
| 2 | Disables the menu using the internal granted dimension |
| 3 | Hides the menu with a third custom dimension |
| 4 | Form Fields also support the propagation of new values to children and parents. This sets the custom dimension of this field and all of its children to true. |
| 5 | This sets the internal default enabled dimension of this field and all of its parents and children to true. |
| 6 | Checks if the custom dimension is set to true |
| 7 | Checks if the internal default dimension is set to true |
| 8 | Checks if all dimensions of formField2 are true |
| 9 | Checks if all dimensions of formField2 and all dimensions of all parent Form Fields are enabled. |
| In the example above the instance 'formField3' uses 4 dimensions for the enabled attribute: ENABLED_CUSTOM because it is explicitly used and the 3 dimensions that are used internally (ENABLED, ENABLED_GRANTED, ENABLED_SLAVE). Even though the instance 'formField2' makes no use of the custom dimension it is consumed for this instance as well because the dimensions do not exist by instance but by attribute (as explained above). |
4. Texts
The TEXTS class is a convenience class to access the default Text Provider Service used for the localization of the texts in the user interface.
TEXTS.get("persons");Its also possible to use some parameters:
String name = "Bob";
int age = 13;
TEXTS.get("NameWithAge", name, age);In this case, some placeholders for the parameters are needed in the translated text:
NameWithAge={0} is {1} years old;4.1. Text properties files
Scout uses the java.util.ResourceBundle mechanism for native language support. So whatever language files you have in your <project-prefix>.shared/resources/texts/*.properties are taken as translation base.
Example setup:
-
<project-prefix>.shared/resources/texts/Texts.properties
-
<project-prefix>.shared/resources/texts/Texts_fr.properties
If your application starts with the -vmargs -Duser.language=fr or eclipse.exe -nl=fr the translations in Texts_fr.properties are considered.
In case of any other user language the translations in Texts.properties are considered.
It is possible to edit these files in the Eclipse Scout SDK with the NLS Editor.
4.2. Text Provider Service
Text Provider Services are services responsible to provide localization for texts in the user interface. A typical application contains a such service contributed by the Shared Project.
-
implements:
ITextProviderService -
extends:
AbstractDynamicNlsTextProviderService(default, translations are stored in properties files)
Using Text Provider Services developers can decide to store the translations in a custom container like a database or XML files. Furthermore using TextProviderServices it is very easy to overwrite any translated text in the application (also texts used in Scout itself) using the service ranking.
The mechanism is aligned with the icon retrieval which is also managed using Icon Provider Services.
4.2.1. Localization using .properties files
By default the internationalization mechanism relies on .properties files using a reference implementation of the TextProviderServices:
Service extending the AbstractDynamicNlsTextProviderService class.
A Text Provider Service working with the default implementation need to define where the properties files are located. This is realized by overriding the getter getDynamicNlsBaseName(). Here an example:
@Override
protected String getDynamicNlsBaseName() {
return "resources.texts.Texts";
}If configured like this, it means that the .properties files will be located in the same plug-in at the location:
-
/resources/texts/Texts.properties(default) -
/resources/texts/Texts_fr.properties(french) -
/resources/texts/Texts_de.properties(german) -
…(additional languages)
If you decide to store your translated texts in .properties files, you migth want to use the NLS Editor to edit them.
You need to respect the format defined by the Java Properties class. In particular the encoding of a .properties file is ISO-8859-1 (also known as Latin-1). All non-Latin-1 characters must be encoded. Examples:
'à' => "\u00E0" 'ç' => "\u00E7" 'ß' => "\u00DF"
The encoding is the "Unicode escape characters": \uHHHH where HHHH is a hexadecimal id of the character in the Unicode character table. Read more on the .properties File on wikipedia.
5. Icons
A lot of Scout widgts support icons. For instance a menu item can show an icon next to the menu text. Icons in Scout can be either a bitmap image (GIF, PNG, JPEG, etc.) or a character from an icon-font. An example for an icon-font is the scoutIcons.ttf which comes shipped with Scout.
It’s a good practice to define the available icons in your application in a
class that defines each icon as a constant. Create a class Icons in the shared
module of your project. These constants should be references, when you set the
IconId property in your code.
For bitmap images you simply specify the filename of the image file without the file extension. Place all your icon files in the resource folder of your client module. Assuming your project name is "org.scout.hello", the correct location to store icon files would be:
org.scout.hello.client/ # Client project directory
src/main/resources/ # Resources directory
org/scout/hello/client/icons/ # Path to icons
application_logo_large.png
person.png
...
// Bitmap image (references icons/application_logo_large.png)
public static final String ApplicationLogo = "application_logo_large";
// Character from icon-font scoutIcons.woff (default)
public static final String Calendar ="font:\uE003";
// Character from a custom icon-font
public static final String Phone ="font:awesomeIcons \uF095";@Override
protected String getConfiguredIconId(){
return Icons.Calendar;
}5.1. Using a custom icon font
You can use your own icon font. The required file format for an icon font is .woff. For the following examples we assume the name of your font file is awesomeIcons.woff. The following steps are required:
Place the font file in the WebContent/res directory of your html.ui module.
This makes it available for http requests on the URL
http://[base]/res/awesomeIcons.woff.
Create a CSS/LESS definition, to reference the icon font in stylesheets. Make sure the definition is added to the LESS module of your project.
@font-face {
font-family: awesomeIcons;
font-weight: normal;
src: url('awesomeIcons.woff') format('woff');
}
/* Overrides definitions in fonts.css > .font-icon
* Use iconId 'font:awesomeIcons [character]' in Scout model.
* See icons.js and usage of this class to see how iconId is used.
*/
.font-awesomeIcons {
font-family: awesomeIcons, @defaultFont;
}To check if your CSS definition is correct, you should download the CSS file
directly via URL and check if the CSS file contains the required font definition.
Assuming your LESS macro is named hello-scout-macro.less the URL is:
http://[base]/res/hello-scout.css
| When you request resources from the /res folder via http, Scout will find resources from parent modules too. Thus the scoutIcons.woff is always available in a Scout project. However, you must avoid naming conflicts, since at runtime all files exist on the same classpath. |
5.2. How to create a custom icon font
Here’s what we do to create and maintain our own icon font scoutIcons.woff. There may be other methods to achieve the same.
To create and modify our icon font we use the online application IcoMoon. IcoMoon allows you to assemble a set of icons from various sources (e.g. FontAwesome or custom SVG graphics) and create a font file from that set.
You can export/import your icon set from and to IcoMoon, and you should store the files exported from IcoMoon in a SCM system like GIT. IcoMoon stores all important data in the file selection.json. Make sure you also store the raw SVG graphics you’ve uploaded to IcoMoon in your SCM, in case you have to change a single icon later.
To edit the icon font in IcoMoon follow these steps:
-
Import selection.json in IcoMoon, click on the "Import Icons" button.
-
With the Select tool (arrow) you select the icons you want to add to your set. You can also add one or more characters from other icon fonts like FontAwesome by choosing Add Icons From Library…
-
Your can import your custom SVG graphics with Import to Set, which you find in the hamburger menu on the icon set. The SVG graphic should have the same size as the other icons in the set and must use only a single color, black. The background must be transparent. Hint: the filename of the SVG graphic should contain the unicode of the character in the font in order to simplify maintencance. Only use unicodes from the Private Use Area from U+E000 to U+F8FF.
-
When you’re happy with your icon set, you hit the Generate Font button in the footer in IcoMoon. On the following page you can set the unicode of each icon/character. Click on the prefences button (cog icon), to set the name of your icon font (e.g. scoutIcons). Finally click on Download and you receive a ZIP file which contains the new selection.json, and font files like .ttf and .woff.
-
When you’ve added new unicodes to the icon font, you should also update Icons.java and add constants for the new characters. When you’re using Scout JS you should also update icons.js and icons.less.
-
Important! don’t forget to check in the new selection.js to your SCM.
5.2.1. Tools
-
Windows tool Character Map: first you must install your custom TrueType Font .ttf in Windows. Simply double-click on the .ttf file and choose Install. After that you can start Character Map and browse through the font.
-
The ZIP archive from IcoMoon contains a file demo.html. This file shows a preview of your icon font. Works in Chrome, but we had trouble viewing the font with Firefox.
-
This tool from Wikipedia also creates a preview for an icon font: Vorlage:Private-Use-Area-Test. Icon font must be installed first.
6. Lookup Call
Lookup calls are mainly used by SmartFields and SmartColumns to look up single or multiple LookupRows.
Class: LookupCall
6.1. Description
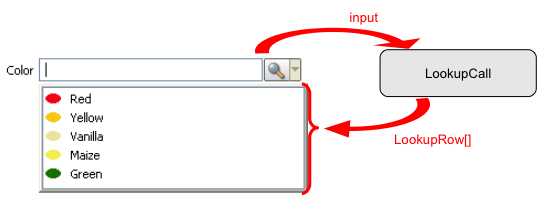
The Lookup call mechanism is used to look up a set of key-text pairs. Whereas the key can be of any Java type the text must be of the type String. Each entry in this set is called LookupRow. In addition to the key and the text a LookupRow can also define and icon, font, colors and a tooltipText.
This schema explains the role of a LookupCall in a SmartField:
6.2. Input
Lookup calls provide different method to compute the set of LookupRows :
-
getDataByKey(): Retrieves a single lookup row for a specific key value. Used by SmartFields and SmartColumns to get the display text for a given key value.
-
getDataByText(): Retrieve multiple lookup rows which match a certain String. Used by SmartFields when the user starts to enter some text in the field.
-
getDataByAll(): Retrieves all available lookup rows. Used by SmartFields when the user clicks on the browse icon.
-
getDataByRec(): This can only be used for hierarchical lookup calls. It retrieves all available sub-tree lookup rows for a given parent.
6.3. Members
The Lookup call contains attributes (accessible with getter and setter) that can be used to compute the list of lookups rows. Out of the box you have:
-
key: contains the key value when the lookup is queried by key.
-
text: contains the text input in case of a text lookup (typically this is the text entered by the user smart field).
-
all: contains the browse hint in case of a lookup by all (typically when a user click on the button to see all proposal in a smart field).
-
rec: contains the key of the parent entry, in when the children of a node are loaded.
-
master: contains the value of the master field (if a master field is associated to the field using the lookup call).
It is possible to add you own additional attributes, for example validityFrom, validityTo as date parameter. Just add them as field with getter and setter:
public class LanguageLookupCall extends LookupCall<String> {
// other stuff like serialVersionUID, Lookup Service definition...
private static final long serialVersionUID = 1L;
private Date m_validityFrom;
private Date m_validityTo;
@Override
protected Class<? extends ILookupService<String>> getConfiguredService() {
return ILanguageLookupService.class;
}
public Date getValidityFrom() {
return m_validityFrom;
}
public void setValidityFrom(Date validityFrom) {
this.m_validityFrom = validityFrom;
}
public Date getValidityTo() {
return m_validityTo;
}
public void setValidityTo(Date validityTo) {
this.m_validityTo = validityTo;
}
}In this case, you might want to set your properties before the lookup call query is sent. This can be done with the PrepareLookup event of the SmartField or the ListBox:
@Override
protected void execPrepareLookup(ILookupCall<String> call) {
LanguageLookupCall c = (LanguageLookupCall) call;
c.setValidityFrom(DateUtility.parse("2012-02-26", "yyyy-mm-dd"));
c.setValidityTo(DateUtility.parse("2013-02-27", "yyyy-mm-dd"));
}If you follow this pattern, you will consume the values on the server by casting the call:
@Override
public List<? extends ILookupRow<String>> getDataByAll(ILookupCall<String> call) {
LanguageLookupCall c = (LanguageLookupCall) call;
Date validityFrom = c.getValidityFrom();
Date validityTo = c.getValidityTo();
List<? extends ILookupRow<String>> result = new ArrayList<>();
//compute result: corresponding lookup rows (depending on validityFrom and validityTo).
return result;
}6.4. Type of lookup calls
6.4.1. With a Lookup Service
Delegation to the Lookup Service on server side.
They are not necessarily restricted to a fix number of records. Instead they should be favoured if the set of records is rather large.
6.4.2. Local Lookup Call
Such a LookupCall is used if the data can be provided directly without the need to make a backend call.
An example of this approach is when a SmartField or a SmartColumn is configured to be used with a CodeType. The code types are cached so it is not necessary to fetch them using a lookup service. Instead a LocalLookupCall, in that case the CodeLookupCall, may be used to load the data. It creates the LookupRows corresponding to the codes in the CodeType.
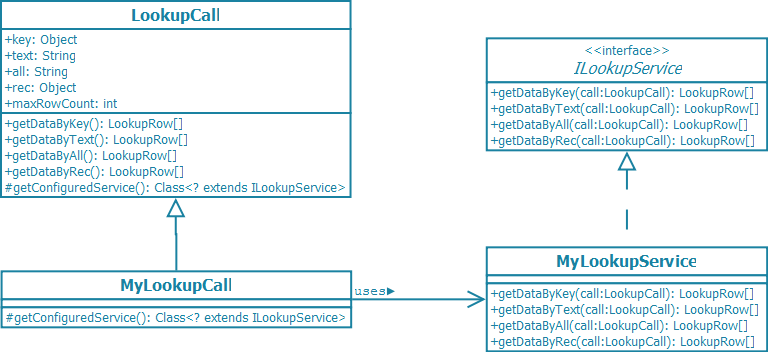
6.4.4. Properties
Defined with getConfiguredXxxxxx() methods.
-
Service: Defines which service is used to retrieve lookup rows
-
MasterRequired: Defines whether a master value must be set in order to query for multiple lookup rows
6.4.5. Code examples
Using a LookupCall in a SmartField:
@Override
protected Class<? extends ILookupCall<String>> getConfiguredLookupCall() {
return LanguageLookupCall.class;
}Accessing a LookupRow directly:
It is possible to access a LookupRow directly. In this example the input is a key (thisKey) and the method getDataByKey() is used. Before accessing the text, we ensure that a LookupRow has been retrieved.
//Execute the LookupCall (using DataByKey)
LookupCall<String> call = new LanguageLookupCall();
call.setKey(thisKey);
List<? extends ILookupRow<String>> rows = call.getDataByKey();
//Get the text (with a null check)
String text = null;
if (rows != null && !rows.isEmpty()) {
text = rows.get(0).getText();
}7. Code Type
A CodeType is a structure to represent a tree key-code association. They are used in SmartField and SmartColumn.
-
implements:
ICodeType<T> -
extends:
AbstractCodeType<T>
7.1. Description
CodeTypes are used in SmartField to let the user choose between a finite list of values. The value stored by the field corresponds to the key of the selected code.
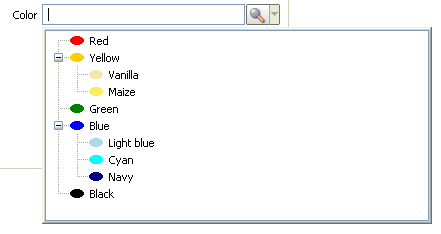
A CodeType can be seen as a tree of Codes. Each code associates to the key (the Id) other properties: among others a Text and an IconId.
In order to have the same resolving mechanism (getting the display text of a key), CodeTypes are also used in SmartColumns. To choose multiple values in the list, the fields ListBox (flat CodeType) and TreeBox (hierarchical CodeType) can be used.
7.1.1. Organisation of the codes
The codes are organized in a tree. Therefore a CodeType can have one or more child codes at the root level, and each code can have other child codes. In a lot of cases a list of codes (meaning a tree containing only leaves at the first level) is sufficient to cover most of the need.
Child codes are ordered in their parent code. This is realized with the order annotation.
7.1.2. Type of the key
The type of the key is defined by its generic parameter <T>. It is very common to use a type from the java.lang.* package (like Integer or String), but any Java Object is suitable. It must:
-
implement
Serializable -
have correctly implemented
equals()andhashCode()functions -
be present in the server and the client
There is no obligation to have the same type for the Id between the codes of a CodeType (meaning the same generic type parameter for the codes inner-class). However it is a good practice to have the same type between the codes of a CodeType, because the Id are used as value of SmartFields. Therefore the generic parameter describing the type of value of a SmartField must be compatible with the type of the codes contained in the CodeType.
7.2. Using a CodeType
7.2.1. SmartField or SmartColumn
CodeType in a SmartField (or SmartColumn).
public class YesOrNoSmartField extends AbstractSmartField<Boolean> {
// other configuration of properties.
@Override
protected Class<? extends ICodeType<?, Boolean>> getConfiguredCodeType() {
return YesOrNoCodeType.class;
}
}If the SmartField (or SmartColumn) works with a CodeType, a specific LookupCall is instantiated to get the LookupRows based on the Codes contained in a CodeType.
7.2.2. Accessing a code directly
Scout-runtime will handle the instantiation and the caching of CodeTypes.
This function returns the text corresponding to the key using a CodeType:
public String getCodeText(boolean key) {
ICode c = BEANS.get(YesOrNoCodeType.class).getCode(key);
if (c != null) {
return c.getText();
}
return null;
}7.3. Static CodeType
7.3.1. Java Code and structure

The common way to define a CodeType is to extend AbstractCodeType. Each code is an inner-class extending AbstractCode. Like usual the properties of Codes and CodeTypes can be set using the getConfiguredXxxxxx() methods.
See the Java Code of a simple YesOrNoCodeType having just two codes:
-
YesOrNoCodeType.YesCode -
YesOrNoCodeType.NoCode
7.4. Dynamic CodeType
Code types are not necessarily hardcoded. It is possible to implement other mechanisms to load a CodeType dynamically.
The description of the Codes can come from a database or from an XML files. If you want to do so, you just need to implement the method corresponding to the event LoadCodes.
It is possible to use the static and the dynamic approach together. In this case, if there is a conflict (2 codes for the same id) the event OverwriteCode is triggered.
Note for advanced users:
Each CodeType is instantiated for
-
each language
-
each partition
Note: A drawback is that the CodeType class is not aware of the language and the partition it is instantiated for. Only the CodeTypeStore that manages the CodeType instances knows for which language and which partition they have been instantiated.
8. Working with exceptions
Exceptions can be logged via SLF4J Logger, or given to exception handler for centralized, consistent exception handling, or translated into other exceptions. Scout provides some few exceptions/errors, which are used by the framework.
8.1. Scout Throwables
All scout throwables are unchecked and typically implementing the IThrowableWithContextInfo interface, which provides functionality for associating context information with the occurred error.
Most scout throwables are runtime exceptions, and typically inherit from PlatformException. See Section 8.1.1 for more information.
Some scout throwables are instances of java.lang.Error by extending PlatformError. Those errors usually provide functionality to interrupt Jobs, for example when a user is canceling a long running operation.
Note: PlatformErrors should never be catched by business logic! See Section 8.1.2 for more information.
8.1.1. Scout Runtime Exceptions
PlatformException
Base runtime exception of the Scout platform, which allows for message formatting anchors and context information to be associated.
There is a single constructor which accepts the exception’s message, and optionally a variable number of arguments. Typically, a potential cause is given as its argument. The message allows further the use of formatting anchors in the form of {} pairs. The respective formatting arguments are provided via the constructor’s varArg parameter. If the last argument is of the type Throwable and not referenced as formatting anchor in the message, that Throwable is used as the exception’s cause. Internally, SLF4J MessageFormatter is used to provide substitution functionality. Hence, The format is the very same as if using SLF4j Logger.
Further, PlatformException allows to associate context information, which are available in Log4j diagnostic context map (MDC) upon logging the exception.
Exception cause = new Exception();
// Create a PlatformException with a message
new PlatformException("Failed to persist data");
// Create a PlatformException with a message and cause
new PlatformException("Failed to persist data", cause);
// Create a PlatformException with a message with formatting anchors
new PlatformException("Failed to persist data [entity={}, id={}]", "person", 123);
// Create a PlatformException with a message containing formatting anchors and a cause
new PlatformException("Failed to persist data [entity={}, id={}]", "person", 123, cause);
// Create a PlatformException with context information associated
new PlatformException("Failed to persist data", cause)
.withContextInfo("entity", "person")
.withContextInfo("id", 123);ProcessingException
Represents a PlatformException and is thrown in case of a processing failure, and which can be associated with an exception error code and severity.
VetoException
Represents a ProcessingException with VETO character. If thrown server-side, exceptions of this type are transported to the client and typically visualized in the form of a message box.
AssertionException
Represents a PlatformException and indicates an assertion error about the application’s assumptions about expected values.
TransactionRequiredException
Represents a PlatformException and is thrown if a ServerRunContext requires a transaction to be available.
8.1.2. Scout Runtime Errors
Runtime Errors are used to indicate an error, that shouldn’t be catched/treated by business logic and therefore bubble up to the appropriate exception handler in the scout framework. Because those errors are handled by the framework internals, they should never be catched on the server (Services etc.) nor on the client side (Pages, Forms, etc.).
All Scout Runtime Errors extend PlatformError.
PlatformError
Like PlatformException, PlatformErrors implement IThrowableWithContextInfo for associating context information with the occurred error. See PlatformException for usage and example code.
ThreadInterruptedError
Represents a PlatformError and indicates that a thread was interrupted while waiting for some condition to become true, e.g. while waiting for a job to complete. Unlike java.lang.InterruptedException, the thread’s interrupted status is not cleared when catching this exception.
FutureCancelledError
Represents a PlatformError and indicates that the result of a job cannot be retrieved, or the IFuture’s completion not be awaited because the job was cancelled.
TimedOutError
Represents a PlatformError and indicates that the maximal wait time elapsed while waiting for some condition to become true, e.g. while waiting a job to complete.
8.2. Exception handling
An exception handler is the central point for exception handling. It provides a single method 'handle' which accepts a Throwable, and which never throws an exception. It is implemented as a bean, meaning managed by the bean manager to allow easy replacement, e.g. to use a different handler when running client or server side.
By default, a ProcessingException is logged according to its severity, a VetoException, ThreadInterruptedError or FutureCancelledError logged in DEBUG level, and any other exception logged as an ERROR. If running client side, exceptions are additionally visualized and showed to the user.
8.3. Exception translation
Exception translators are used to translate an exception into another exception.
Also, they unwrap the cause of wrapper exceptions, like UndeclaredThrowableException, or InvocationTargetException, or ExecutionException. If the exception is of the type Error, it is normally not translated, but re-thrown instead. That is because an Error indicates a serious problem due to an abnormal condition.
8.3.1. DefaultExceptionTranslator
Use this translator to work with checked exceptions and runtime exceptions, but not with Throwable.
If given an Exception, or a RuntimeException, or if being a subclass thereof, that exception is returned as given. Otherwise, a PlatformException is returned which wraps the given Throwable.
8.3.2. DefaultRuntimeExceptionTranslator
Use this translator to work with runtime exceptions. When working with RunContext or IFuture, some methods optionally accept a translator. If not specified, this translator is used by default.
If given a RuntimeException, it is returned as given. For a checked exception, a PlatformException is returned which wraps the given checked exception.
8.3.3. PlatformExceptionTranslator
Use this translator to work with PlatformExceptions.
If given a PlatformException, it is returned as given. For all other exceptions (checked or unchecked), a PlatformException is returned which wraps the given exception.
Typically, this translator is used if you require to add some context information via IThrowableWithContextInfo.withContextInfo(String, Object, Object).
try {
// do something
}
catch (Exception e) {
throw BEANS.get(PlatformExceptionTranslator.class).translate(e)
.withContextInfo("cid", "12345")
.withContextInfo("user", Subject.getSubject(AccessController.getContext()))
.withContextInfo("job", IFuture.CURRENT.get());
}8.3.4. NullExceptionTranslator
Use this translator to work with Throwable as given.
Also, if given a wrapped exception like UndeclaredThrowableException, InvocationTargetException or ExecutionException, that exception is returned as given without unwrapping its cause.
For instance, this translator can be used if working with the Job API, e.g. to distinguish between a FutureCancelledError thrown by the job’s runnable, or because the job was effectively cancelled.
8.4. Exception Logging
Scout framework logs via SLF4J (Simple Logging Facade for Java). It serves as a simple facade or abstraction for various logging frameworks (e.g. java.util.logging, logback, log4j) allowing the end user to plug in the desired logging framework at deployment time.
SLF4J allows the use of formatting anchors in the form of {} pairs in the message which will be replaced by the respective argument. If the last argument is of the type Throwable and not referenced as formatting anchor in the message, that Throwable is used as the exception.
Exception e = new Exception();
Logger logger = LoggerFactory.getLogger(getClass());
// Log a message
logger.error("Failed to persist data");
// Log a message with exception
logger.error("Failed to persist data", e);
// Log a message with formatting anchors
logger.error("Failed to persist data [entity={}, id={}]", "person", 123);
// Log a message and exception with a message containing formatting anchors
logger.error("Failed to persist data [entity={}, id={}]", "person", 123, e);9. JobManager
Scout provides a job manager based on Java Executors framework to run tasks in parallel, and on Quartz Trigger API to support for schedule plans and to compute firing times. A task (aka job) can be scheduled to commence execution either immediately upon being scheduled, or delayed some time in the future. A job can be single executing, or recurring based on some schedule plan. The job manager itself is implemented as an application scoped bean, meaning that it is a singleton which exists once in the web application.
9.1. Functionality
-
immediate, delayed or timed execution
-
single (one-shot) or repetitive execution (based on Quartz schedule plans)
-
listen for job lifecycle events
-
wait for job completion
-
job cancellation
-
limitation of the maximal concurrently level among jobs
-
RunContextbased execution -
configurable thread pool size (core pool size, max pool size)
-
association of job execution hints to select jobs (e.g. to cancel or await job’s completion)
-
named jobs and threads to ease debugging
9.2. Job
A job is defined as some work to be executed asynchronously and is associated with a JobInput to describe how to run that work. The work is given to the job manager in the form of a Runnable or Callable. The only difference is, that a Runnable represents a 'fire-and-forget' action, meaning that the submitter of the job does not expect the job to return a result. On the other hand, a Callable returns the computation’s result, which the submitter can await for. Of course, a runnable’s completion can also be waited for.
public class Work implements IRunnable {
@Override
public void run() throws Exception {
// do some work
}
}public class WorkWithResult implements Callable<String> {
@Override
public String call() throws Exception {
// do some work
return "result";
}
}Upon scheduling a job, the job manager returns a IFuture to interact with the job, e.g. to cancel its execution, or to await its completion. The job itself can also access its IFuture, namely via IFuture.CURRENT() ThreadLocal.
public class Job implements IRunnable {
@Override
public void run() throws Exception {
IFuture<?> myFuture = IFuture.CURRENT.get();
}
}9.3. Scheduling a Job
The job manager provides two scheduling methods, which only differ in the work they accept for execution (callable or runnable).
IFuture<Void> schedule(IRunnable runnable, JobInput input); (1)
<RESULT> IFuture<RESULT> schedule(Callable<RESULT> callable, JobInput input); (2)| 1 | Use to schedule a runnable which does not return a result to the submitter |
| 2 | Use to schedule a callable which does return a result to the submitter |
The second and mandatory argument to be provided is the JobInput, which tells the job manager how to run the job. Learn more about JobInput.
The following snippet illustrates how a job is actually scheduled.
IJobManager jobManager = BEANS.get(IJobManager.class); (1)
(2)
jobManager.schedule(() -> {
// do something
}, BEANS.get(JobInput.class)); (3)| 1 | Obtain the job manager via bean manager (application scoped bean) |
| 2 | Provide the work to be executed (either runnable or callable) |
| 3 | Provide the JobInput to instrument job execution |
This looks a little bit clumsy, which is why Scout provides you with the Jobs class to simplify dealing with the job manager, and to support you in the creation of job related artifacts like JobInput, filter builders and more. Most importantly, it allows to schedule jobs in a shorter and more readable form.
Jobs.schedule(() -> {
// do something
}, Jobs.newInput());9.4. JobInput
The job input tells the job manager how to run the job. It further names the job to ease debugging, declares in which context to run the job, and how to deal with unhandled exceptions. The job input itself is a bean, useful if adding some additional features to the job manager. The API of JobInput supports for method chaining for reduced and more solid code.
Jobs.schedule(() -> {
// do something
}, Jobs.newInput()
.withName("job name") (1)
.withRunContext(ClientRunContexts.copyCurrent()) (2)
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withStartIn(10, TimeUnit.SECONDS) (3)
.withSchedule(FixedDelayScheduleBuilder.repeatForever(5, TimeUnit.SECONDS))) (4)
.withExceptionHandling(new ExceptionHandler() { (5)
@Override
public void handle(Throwable t) {
System.err.println(t);
}
}, true));This snippet instructs the job manager to run the job as following:
| 1 | Give the job a name. |
| 2 | Run the job in the current calling context, meaning in the very same context as the submitter is running when giving this job to the job manager. By copying the current context, the job will also be cancelled upon cancellation of the current RunContext. |
| 3 | Commence execution in 10 seconds (delayed execution). |
| 4 | Execute the job repeatedly, with a delay of 5 seconds between the termination of one and the commencement of the next execution. Also, repeat the job infinitely, until being cancelled. |
| 5 | Print any uncaught exception to the error console, and do not propagate the exception to the submitter, nor cancel the job upon an uncaught exception. |
The following paragraphs describe the functionality of JobInput in more detail.
9.4.1. JobInput.withName
To optionally specify the name of the job, which is used to name the worker thread (only in development environment) and for logging purpose. Optionally, formatting anchors in the form of {} pairs can be used in the name, which will be replaced by the respective argument.
Jobs.newInput()
.withName("Sending emails [from={}, to={}]", "frank", "john@eclipse.org, jack@eclipse.org");9.4.2. JobInput.withRunContext
To optionally specify the RunContext to be installed during job execution.
The RunMonitor associated with the RunContext will be used as the job’s monitor, meaning that cancellation requests to the job future or the context’s monitor are equivalent. If no context is given, the job manager ensures a monitor to be installed, so that executing code can always query its cancellation status via RunMonitor.CURRENT.get().isCancelled().
9.4.3. JobInput.withExecutionTrigger
To optionally set the trigger to define the schedule upon which the job will commence execution. If not set, the job will commence execution immediately after being scheduled, and will execute exactly once.
The trigger mechanism is provided by Quartz Scheduler, meaning that you can profit from the powerful Quartz schedule capabilities.
For more information, see http://www.quartz-scheduler.org.
Use the static factory method Jobs.newExecutionTrigger() to get an instance:
// Schedules a delayed single executing job
Jobs.newInput()
.withName("job")
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withStartIn(10, TimeUnit.SECONDS));
// Schedules a repeatedly running job at a fixed rate (every hour), which ends in 24 hours
Jobs.newInput()
.withName("job")
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withEndIn(1, TimeUnit.DAYS)
.withSchedule(SimpleScheduleBuilder.repeatHourlyForever()));
// Schedules a job which runs at 10:15am every Monday, Tuesday, Wednesday, Thursday and Friday
Jobs.newInput()
.withName("job")
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withSchedule(CronScheduleBuilder.cronSchedule("0 15 10 ? * MON-FRI")));Learn more about ExecutionTrigger.
9.4.4. JobInput.withExecutionSemaphore
To optionally control the maximal concurrently level among jobs assigned to the same semaphore.
With a semaphore in place, this job only commences execution, once a permit is free or gets available. If free, the job commences execution immediately at the next reasonable opportunity, unless no worker thread is available.
A semaphore initialized to one allows to run jobs in a mutually exclusive manner, and a semaphore initialized to zero to run no job at all. The number of total permits available can be changed at any time, which allows to adapt the maximal concurrency level to some dynamic criteria like time of day or system load. However, a semaphore can be sealed, meaning that the number of permits cannot be changed anymore, and any attempts will be rejected.
A new semaphore instance can be obtained via Jobs class.
IExecutionSemaphore semaphore = Jobs.newExecutionSemaphore(5); (1)
for (int i = 0; i < 100; i++) {
(2)
Jobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("job-{}", i)
.withExecutionSemaphore(semaphore)); (3)
}| 1 | Create a new ExecutionSemaphore via Jobs class. The semaphore is initialized with 5 permits, meaning that at any given time, there are no more than 5 jobs running concurrently. |
| 2 | Schedule 100 jobs in a row. |
| 3 | Set the semaphore to limit the maximal concurrency level to 5 jobs. |
Learn more about ExecutionSemaphore.
9.4.5. JobInput.withExecutionHint
To associate the job with an execution hint. An execution hint is simply a marker to mark a job, and can be evaluated by filters to select jobs, e.g. to listen to job lifecycle events of some particular jobs, or to wait for some particular jobs to complete, or to cancel some particular jobs. A job may have multiple hints associated. Further, hints can be registered directly on the future via IFuture.addExecutionHint(hint), or removed via IFuture.removeExecutionHint(hint).
9.4.6. JobInput.withExceptionHandling
To control how to deal with uncaught exceptions.
By default, an uncaught exception is handled by ExceptionHandler bean and then propagated to the submitter, unless the submitter is not waiting for the job to complete via IFuture.awaitDoneAndGet().
This method expects two arguments: an optional exception handler, and a boolean flag indicating whether to swallow exceptions. 'Swallow' is independent of the specified exception handler, and indicates whether an exception should be propagated to the submitter, or swallowed otherwise.
If running a repetitive job with swallowing set to true, the job will continue its repetitive execution upon an uncaught exception. If set to false, the execution would exit.
9.4.7. JobInput.withThreadName
To set the thread name of the worker thread that will execute the job.
9.4.8. JobInput.withExpirationTime
To set the maximal expiration time upon which the job must commence execution. If elapsed, the job is cancelled and does not commence execution. By default, a job never expires.
For a job that executes once, the expiration is evaluated just before it commences execution. For a job with a repeating schedule, it is evaluated before every single execution.
In contrast, the trigger’s end time specifies the time at which the trigger will no longer fire. However, if fired, the job may not be executed immediately at this time, which depends on whether having to compete for an execution permit first. So the end time may already have elapsed once commencing execution. In contrast, the expiration time is evaluated just before starting execution.
9.5. IFuture
A future represents the result of an asynchronous computation, and is returned by the job manager upon scheduling a job. The future provides functionality to await for the job to complete, or to get its computation result or exception, or to cancel its execution, and more.
Learn more about job cancellation in Section 9.9.
Learn more about listening for job lifecycle events in Section 9.10.
Learn more about awaiting the job’s completion in Section 9.11.
9.6. Job states
Upon scheduling a job, the job transitions different states. The current state of a job can be queried from its associated IFuture.
| state | description |
|---|---|
SCHEDULED |
Indicates that a job was given to the job manager for execution. |
REJECTED |
Indicates that a job was rejected for execution. This might happen if the job manager has been shutdown, or if no more worker threads are available. |
PENDING |
Indicates that a job’s execution is pending, either because scheduled with a delay, or because of being a repetitive job while waiting for the commencement of the next execution. |
RUNNING |
Indicates that a job is running. |
DONE |
Indicates that a job finished execution, either normally or because it was cancelled. Use |
WAITING_FOR_PERMIT |
Indicates that a semaphore aware job is competing for a permit to become available. |
WAITING_FOR_BLOCKING_CONDITION |
Indicates that a job is blocked by a blocking condition, and is waiting for it to fall. |
| The state 'done' does not necessarily imply that the job already finished execution. That is because a job also enters 'done' state upon cancellation, but may still continue execution. |
9.7. Future filter
A future filter is a filter which can be passed to various methods of the job manager to select some futures. The filter must implement IFilter interface, and has a single method to accept futures of interest.
public class FutureFilter implements Predicate<IFuture<?>> {
@Override
public boolean test(IFuture<?> future) {
// Accept or reject the future
return false;
}
}Scout provides you with FutureFilterBuilder class to ease building filters which match multiple criteria joined by logical 'AND' operation.
Predicate<IFuture<?>> filter = Jobs.newFutureFilterBuilder() (1)
.andMatchExecutionHint("computation") (2)
.andMatchNotState(JobState.PENDING) (3)
.andAreSingleExecuting() (4)
.andMatchNotFuture(IFuture.CURRENT.get()) (5)
.andMatchRunContext(ClientRunContext.class) (6)
.andMatch(new SessionFutureFilter(ISession.CURRENT.get())) (7)
.toFilter(); (8)| 1 | Returns an instance of the future filter builder |
| 2 | Specifies to match only futures associated with execution hint 'computation' |
| 3 | Specifies to match only jobs not in state pending |
| 4 | Specifies to match only single executing jobs, meaning no recurring jobs |
| 5 | Specifies to exclude the current future (if any) |
| 6 | Specifies to match only jobs running on behalf of a ClientRunContext |
| 7 | Specifies to match only jobs of the current session |
| 8 | Builds the filters to get a Filter instance |
Fore more information, refer to the JavaDoc of FutureFilterBuilder.
9.8. Event filter
A job event filter is a filter which can be given to job manager to subscribe for job lifecycle events. The filter must implement IFilter interface, and has a single method to accept events of interest.
public class EventFilter implements Predicate<JobEvent> {
@Override
public boolean test(JobEvent event) {
// Accept or reject the event
return false;
}
}Scout provides you with JobEventFilterBuilder class to ease building filters which match multiple criteria joined by logical 'AND' operation.
Predicate<JobEvent> filter = Jobs.newEventFilterBuilder() (1)
.andMatchEventType(JobEventType.JOB_STATE_CHANGED) (2)
.andMatchState(JobState.RUNNING) (3)
.andMatch(new SessionJobEventFilter(ISession.CURRENT.get())) (4)
.andMatchExecutionHint("computation") (5)
.toFilter(); (6)| 1 | Returns an instance of the job event filter builder |
| 2 | Specifies to match all events representing a job state change |
| 3 | Specifies to match only events for jobs which transitioned into running state |
| 4 | Specifies to match only events for jobs of the current session |
| 5 | Specifies to match only events for jobs which are associated with the execution hint 'computation' |
| 6 | Builds the filters to get a Filter instance |
Fore more information, refer to the JavaDoc of JobEventFilterBuilder.
9.9. Job cancellation
A job can be cancelled in two ways, either directly via its IFuture, or via job manager. Both expect you to provide a boolean flag indicating whether to interrupt the executing working thread. Upon cancellation, the job immediately enters 'done' state. Learn more about Section 9.6. If cancelling via job manager, a future filter must be given to select the jobs to be cancelled. Learn more about Section 9.7
The cancellation attempt will be ignored if the job has already completed or was cancelled. If not running yet, the job will never run. If the job has already started, then the interruptIfRunning parameter determines whether the thread executing the job should be interrupted in an attempt to stop the job.
In the following some examples:
// Schedule a job
IFuture<?> future = Jobs.schedule(new Work(), Jobs.newInput());
// Cancel the job via its future
future.cancel(false);Jobs.getJobManager().cancel(Jobs.newFutureFilterBuilder()
.andMatchFuture(future1, future2, future3)
.toFilter(), false);Jobs.getJobManager().cancel(Jobs.newFutureFilterBuilder()
.andMatchExecutionHint("computation")
.andMatch(new SessionFutureFilter(ISession.CURRENT.get()))
.toFilter(), false);A job can query its current cancellation status via RunMonitor.CURRENT.get().isCancelled(). If doing some long running operations, it is recommended for the job to regularly check for cancellation.
A job which is scheduled to run on a copy of the submitting RunContext, it gets also cancelled once the RunMonitor of that context gets cancelled.
|
9.10. Subscribe for job lifecycle events
Sometimes it is useful to register for some job lifecycle events. The following event types can be subscribed for:
| state | description |
|---|---|
JOB_STATE_CHANGED |
Signals that a job transitioned to a new JobState, e.g. form JobState.SCHEDULED to JobState.RUNNING. |
JOB_EXECUTION_HINT_ADDED |
Signals that an execution hint was added to a job. |
JOB_EXECUTION_HINT_REMOVED |
Signals that an execution hint was removed from a job. |
JOB_MANAGER_SHUTDOWN |
Signals that the job manager was shutdown. |
The listener is registered via job manager as following:
Jobs.getJobManager().addListener(Jobs.newEventFilterBuilder() (1)
.andMatchEventType(JobEventType.JOB_STATE_CHANGED)
.andMatchState(JobState.RUNNING)
.andMatch(new SessionJobEventFilter(ISession.CURRENT.get()))
.toFilter(), event -> {
IFuture<?> future = event.getData().getFuture(); (2)
System.out.println("Job commences execution: " + future.getJobInput().getName());
});| 1 | Subscribe for all events related to jobs just about to commence execution, and which belong to the current session |
| 2 | Get the future this event was fired for |
If interested in only events of a single future, the listener can be registered directly on the future.
future.addListener(Jobs.newEventFilterBuilder()
.andMatchEventType(JobEventType.JOB_STATE_CHANGED)
.andMatchState(JobState.RUNNING)
.toFilter(), event -> System.out.println("Job commences execution"));9.11. Awaiting job completion
A job’s completion can be either awaited on its IFuture, or via job manager - the first optionally allows to consume the job’s computation result, whereas the second allows multiple futures to be awaited for.
9.11.1. Difference between 'done' and 'finished' state
When awaiting futures, the definition of 'done' and 'finished' state should be understood - 'done' means that the future completed either normally, or was cancelled. But, if cancelled while running, the job may still continue its execution, whereas a job which not commenced execution yet, will never do so. The latter typically applies for jobs scheduled with a delay. However, 'finished' state differs from 'done' state insofar as a cancelled, currently running job enters 'finished' state only upon its actual completion. Otherwise, if not cancelled, or cancelled before executing, it is equivalent to 'done' state. In most situations, it is sufficient to await for the future’s done state, especially because a cancelled job cannot return a result to the submitter anyway.
9.11.2. Awaiting a single future’s 'done' state
Besides of some overloaded methods, IFuture basically provides two methods to wait for a future to enter 'done' state, namely awaitDone and awaitDoneAndGet, with the difference that the latter additionally returns the job’s result or exception. If the future is already done, those methods will return immediately. For both methods, there exists an overloaded version to wait for at most a given time, which once elapsed results in a TimedOutError thrown.
Further, awaitDoneAndGet allows to specify an IExceptionTranslator to control exception translation. By default, DefaultRuntimeExceptionTranslator is used, meaning that a RuntimeException is propagated as it is, whereas a checked exception would be wrapped into a PlatformException. If you require checked exceptions to be thrown as they are, use DefaultExceptionTranslator instead, or even NullExceptionTranslator to work with the raw ExecutionException as being thrown by Java Executor framework.
IFuture<String> future = Jobs.schedule(() -> {
// doing something
return "computation result";
}, Jobs.newInput());
// Wait until done without consuming the result
future.awaitDone(); (1)
future.awaitDone(10, TimeUnit.SECONDS); (2)
// Wait until done and consume the result
String result = future.awaitDoneAndGet(); (3)
result = future.awaitDoneAndGet(10, TimeUnit.SECONDS); (4)
// Wait until done, consume the result, and use a specific exception translator
result = future.awaitDoneAndGet(DefaultExceptionTranslator.class); (5)
result = future.awaitDoneAndGet(10, TimeUnit.SECONDS, DefaultExceptionTranslator.class); (6)| 1 | Waits if necessary for the job to complete, or until cancelled. This method does not throw an exception if cancelled or the computation failed, but throws ThreadInterruptedError if the current thread was interrupted while waiting. |
| 2 | Waits if necessary for at most 10 seconds for the job to complete, or until cancelled, or the timeout elapses. This method does not throw an exception if cancelled, or the computation failed, but throws TimedOutError if waiting timeout elapsed, or throws ThreadInterruptedError if the current thread was interrupted while waiting. |
| 3 | Waits if necessary for the job to complete, and then returns its result, if available, or throws its exception according to DefaultRuntimeExceptionTranslator, or throws FutureCancelledError if cancelled, or throws ThreadInterruptedError if the current thread was interrupted while waiting. |
| 4 | Waits if necessary for at most 10 seconds for the job to complete, and then returns its result, if available, or throws its exception according to DefaultRuntimeExceptionTranslator, or throws FutureCancelledError if cancelled, or throws TimedOutError if waiting timeout elapsed, or throws ThreadInterruptedError if the current thread was interrupted while waiting. |
| 5 | Waits if necessary for the job to complete, and then returns its result, if available, or throws its exception according to the given DefaultExceptionTranslator, or throws FutureCancelledError if cancelled, or throws ThreadInterruptedError if the current thread was interrupted while waiting. |
| 6 | Waits if necessary for at most the given time for the job to complete, and then returns its result, if available, or throws its exception according to the given DefaultExceptionTranslator, or throws FutureCancelledError if cancelled, or throws TimedOutError if waiting timeout elapsed, or throws ThreadInterruptedError if the current thread was interrupted while waiting. |
It is further possible to await asynchronously on a future to enter done state by registering a callback via whenDone method. The advantage over registering a listener is that the callback is invoked even if the future already entered done state upon registration.
future.whenDone(event -> {
// invoked upon entering done state.
}, ClientRunContexts.copyCurrent());Because invoked in another thread, this method optionally accepts a RunContext to be applied when being invoked.
9.11.3. Awaiting a single future’s 'finished' state
Use the method awaitFinished to wait for the job to finish, meaning that the job either completed normally or by an exception, or that it will never commence execution due to a premature cancellation. To learn more about the difference between 'done' and 'finished' state, click here.
Please note that this method does not return the job’s result, because by Java Future definition, a cancelled job cannot provide a result.
IFuture<String> future = Jobs.schedule(() -> {
// doing something
return "computation result";
}, Jobs.newInput());
// Wait until finished
future.awaitFinished(10, TimeUnit.SECONDS);9.11.4. Awaiting multiple future’s 'done' state
Job Manager allows to await for multiple futures at once. The filter to be provided limits the futures to await for. This method requires you to provide a maximal time to wait.
Filters can be plugged by using logical filters like AndFilter or OrFilter, or negated by enclosing a filter in NotFilter. Also see Section 9.7 to create a filter to match multiple criteria joined by logical 'AND' operation.
// Wait for some futures
Jobs.getJobManager().awaitDone(Jobs.newFutureFilterBuilder() (1)
.andMatchFuture(future1, future2, future3)
.toFilter(), 1, TimeUnit.MINUTES);
// Wait for all futures marked as 'reporting' jobs of the current session
Jobs.getJobManager().awaitDone(Jobs.newFutureFilterBuilder() (2)
.andMatchExecutionHint("reporting")
.andMatch(new SessionFutureFilter(ISession.CURRENT.get()))
.toFilter(), 1, TimeUnit.MINUTES);| 1 | Waits if necessary for at most 1 minute for all three futures to complete, or until cancelled, or the timeout elapses. |
| 2 | Waits if necessary for at most 1 minute until all jobs marked as 'reporting' jobs of the current session complete, or until cancelled, or the timeout elapses. |
9.11.5. Awaiting multiple future’s 'finished' state
Use the method awaitFinished to wait for multiple jobs to finish, meaning that the jobs either completed normally or by an exception, or that they will never commence execution due to a premature cancellation. To learn more about the difference between 'done' and 'finished' state, click here.
// Wait for some futures
Jobs.getJobManager().awaitFinished(Jobs.newFutureFilterBuilder() (1)
.andMatchFuture(future1, future2, future3)
.toFilter(), 1, TimeUnit.MINUTES);
// Wait for all futures marked as 'reporting' jobs of the current session
Jobs.getJobManager().awaitFinished(Jobs.newFutureFilterBuilder() (2)
.andMatchExecutionHint("reporting")
.andMatch(new SessionFutureFilter(ISession.CURRENT.get()))
.toFilter(), 1, TimeUnit.MINUTES);| 1 | Waits if necessary for at most 1 minute for all three futures to finish, or until cancelled, or the timeout elapses. |
| 2 | Waits if necessary for at most 1 minute until all jobs marked as 'reporting' jobs of the current session finish, or until cancelled, or the timeout elapses. |
9.12. Uncaught job exceptions
If a job throws an exception, that exception is handled by ExceptionHandler, and propagated to the submitter. However, the exception is only propagated if having a waiting submitter. Also, an uncaught exception causes repetitive jobs to terminate.
This default behavior as described can be changed via JobInput.withExceptionHandling(..).
9.13. Blocking condition
A blocking condition allows a thread to wait for a condition to become true. That is similar to the Java Object’s 'wait/notify' mechanism, but with some additional functionality regarding semaphore aware jobs. If a semaphore aware job enters a blocking condition, it releases ownership of the permit, which allows another job of that same semaphore to commence execution. Upon the condition becomes true, the job then must compete for a permit anew.
A condition can be used across multiple threads to wait for the same condition. Also, a condition is reusable upon invalidation. And finally, a condition can be used even if not running within a job.
A blocking condition is often used by model jobs to wait for something to happen, but to allow another model job to run while waiting. A typical use case would be to wait for a MessageBox to be closed.
9.13.1. Example of a blocking condition
You are running in a semaphore aware job and require to do some long running operation. During that time you do not require to be the permit owner. A simple but wrong approach would be the following:
// Schedule a long running operation.
IFuture<?> future = Jobs.schedule(new LongRunningOperation(), Jobs.newInput());
// Wait until done.
future.awaitDone();The problem with this approach is, that you still are the permit owner while waiting, meaning that you possibly prevent other jobs from running. Instead, you could use a blocking condition for that to achieve:
// Create a blocking condition.
final IBlockingCondition operationCompleted = Jobs.newBlockingCondition(true);
// Schedule a long running operation.
IFuture<Void> future = Jobs.schedule(new LongRunningOperation(), Jobs.newInput());
// Register done callback to unblock the condition.
future.whenDone(event -> {
// Let the waiting job re-acquire a permit and continue execution.
operationCompleted.setBlocking(false);
}, null);
// Wait until done. Thereby, the permit of the current job is released for the time while waiting.
operationCompleted.waitFor();9.14. ExecutionSemaphore
Represents a fair counting semaphore used in Job API to control the maximal number of jobs running concurrently.
Jobs which are assigned to the same semaphore run concurrently until they reach the maximal concurrency level defined for that semaphore. Subsequent tasks then wait in the queue until a permit becomes available.
A semaphore initialized to one allows to run jobs in a mutually exclusive manner, and a semaphore initialized to zero to run no job at all. The number of total permits available can be changed at any time, which allows to adapt the maximal concurrency level to some dynamic criteria like time of day or system load. However, once calling seal(), the number of permits cannot be changed anymore, and any attempts will result in an AssertionException. By default, a semaphore is unbounded.
9.15. ExecutionTrigger
Component that defines the schedule upon which a job will commence execution.
A trigger can be as simple as a 'one-shot' execution at some specific point in time in the future, or represent a schedule which executes a job on a repeatedly basis. The latter can be configured to run infinitely, or to end at a specific point in time. It is further possible to define rather complex triggers, like to execute a job every second Friday at noon, but with the exclusion of all the business’s holidays.
See the various schedule builders provided by Quartz Scheduler:
SimpleScheduleBuilder, CronScheduleBuilder, CalendarIntervalScheduleBuilder, DailyTimeIntervalScheduleBuilder. The most powerful builder is CronScheduleBuilder. Cron is a UNIX tool with powerful and proven scheduling capabilities. For more information, see http://www.quartz-scheduler.org.
Additionally, Scout provides you with FixedDelayScheduleBuilder to run a job with a fixed delay between the termination of one execution and the commencement of the next execution.
Use the static factory method 'Jobs.newExecutionTrigger()' to get an instance.
9.15.1. Misfiring
Regardless of the schedule used, job manager guarantees no concurrent execution of the same job. That may happen, if using a repeatedly schedule with the job not terminated its last execution yet, but the schedule’s trigger would like to fire for the next execution already. Such a situation is called a misfiring. The action to be taken upon a misfiring is configurable via the schedule’s misfiring policy. A policy can be to run the job immediately upon termination of the previous execution, or to just ignore that missed firing. See the JavaDoc of the schedule for more information.
9.16. Stopping the platform
Upon stopping the platform, the job manager will also be shutdown. If having a IPlatformListener to perform some cleanup work, and which requires the job manager to be still functional, that listener must be annotated with an @Order less than IJobManager.DESTROY_ORDER, which is 5'900. If not specifying an @Order explicitly, the listener will have the default order of 5, meaning being invoked before job manager shutdown anyway.
9.17. ModelJobs
Model jobs exist client side only, and are used to interact with the Scout client model to read and write model values in a serial manner per session. That enables no synchronization to be used when interacting with the model.
By definition, a model job requires to be run on behalf of a ClientRunContext with a IClientSession set, and must have the session’s model job semaphore set as its ExecutionSemaphore. That causes all such jobs to be run in sequence in the model thread. At any given time, there is only one model thread active per client session.
The class ModelJobs is a helper class, and is for convenience purpose to facilitate the creation of model job related artifacts, and to schedule model jobs.
(1)
ModelJobs.schedule(() -> {
// doing something in model thread
}, ModelJobs.newInput(ClientRunContexts.copyCurrent()) (2)
.withName("Doing something in model thread"));| 1 | Schedules the work to be executed in the model thread |
| 2 | Creates the JobInput to become a model job, meaning with the session’s model job semaphore set |
For model jobs, it is also allowed to run according to a Quartz schedule plan, or to be executed with a delay. Then the model permit is acquired just before each execution, and not upon being scheduled.
Furthermore, the class ModelJobs provides some useful static methods:
// Returns true if the current thread represents the model thread for the current client session. At any given time, there is only one model thread active per client session.
ModelJobs.isModelThread();
// Returns true if the given Future belongs to a model job.
ModelJobs.isModelJob(IFuture.CURRENT.get());
// Returns a builder to create a filter for future objects representing a model job.
ModelJobs.newFutureFilterBuilder();
// Returns a builder to create a filter for JobEvent objects originating from model jobs.
ModelJobs.newEventFilterBuilder();
// Instructs the job manager that the current model job is willing to temporarily yield its current model job permit. It is rarely appropriate to use this method. It may be useful for debugging or testing purposes.
ModelJobs.yield();9.18. Configuration
Job manager can be configured with properties starting with scout.jobmanager. See Section 2.5.
9.19. Extending job manager
Job manager is implemented as an application scoped bean, and which can be replaced. To do so, create a class which extends JobManager, and annotate it with @Replace annotation. Most likely, you like to use the EE container’s ThreadPoolExecutor, or to contribute some behavior to the callable chain which finally executes the job.
To change the executor, overwrite createExecutor method and return the executor of your choice. But do not forget to register a rejection handler to reject futures upon rejection. Also, overwrite shutdownExecutor to not shutdown the container’s executor.
To contribute some behavior to the callable chain, overwrite the method interceptCallableChain and contribute your decorator or interceptor. Refer to the method’s JavaDoc for more information.
9.20. Scheduling examples
This sections contains some common scheduling examples.
Jobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("Running once")
.withRunContext(ClientRunContexts.copyCurrent()));Jobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("Running in 10 seconds")
.withRunContext(ClientRunContexts.copyCurrent())
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withStartIn(10, TimeUnit.SECONDS))); // delay of 10 secondsJobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("Running every minute")
.withRunContext(ClientRunContexts.copyCurrent())
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withStartIn(1, TimeUnit.MINUTES) (1)
.withSchedule(SimpleScheduleBuilder.simpleSchedule() (2)
.withIntervalInMinutes(1) (3)
.repeatForever()))); (4)| 1 | Configure to fire in 1 minute for the first time |
| 2 | Use Quartz simple schedule to achieve fixed-rate execution |
| 3 | Repetitively fire every minute |
| 4 | Repeat forever |
Jobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("Running every minute for total 60 times")
.withRunContext(ClientRunContexts.copyCurrent())
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withStartIn(1, TimeUnit.MINUTES) (1)
.withSchedule(SimpleScheduleBuilder.simpleSchedule() (2)
.withIntervalInMinutes(1) (3)
.withRepeatCount(59)))); (4)| 1 | Configure to fire in 1 minute for the first time |
| 2 | Use Quartz simple schedule to achieve fixed-rate execution |
| 3 | Repetitively fire every minute |
| 4 | Repeat 59 times, plus the initial execution |
Jobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("Running forever with a delay of 1 minute between the termination of the previous and the next execution")
.withRunContext(ClientRunContexts.copyCurrent())
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withStartIn(1, TimeUnit.MINUTES) (1)
.withSchedule(FixedDelayScheduleBuilder.repeatForever(1, TimeUnit.MINUTES)))); (2)| 1 | Configure to fire in 1 minute for the first time |
| 2 | Use fixed delay schedule |
Jobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("Running 60 times with a delay of 1 minute between the termination of the previous and the next execution")
.withRunContext(ClientRunContexts.copyCurrent())
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withStartIn(1, TimeUnit.MINUTES) (1)
.withSchedule(FixedDelayScheduleBuilder.repeatForTotalCount(60, 1, TimeUnit.MINUTES)))); (2)| 1 | Configure to fire in 1 minute for the first time |
| 2 | Use fixed delay schedule |
Jobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("Running at 10:15am every Monday, Tuesday, Wednesday, Thursday and Friday")
.withRunContext(ClientRunContexts.copyCurrent())
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withSchedule(CronScheduleBuilder.cronSchedule("0 15 10 ? * MON-FRI")))); (1)| 1 | Cron format: [second] [minute] [hour] [day_of_month] [month] [day_of_week] [year]? |
Jobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("Running every minute starting at 14:00 and ending at 14:05, every day")
.withRunContext(ClientRunContexts.copyCurrent())
.withExecutionTrigger(Jobs.newExecutionTrigger()
.withSchedule(CronScheduleBuilder.cronSchedule("0 0-5 14 * * ?")))); (1)| 1 | Cron format: [second] [minute] [hour] [day_of_month] [month] [day_of_week] [year]? |
IExecutionSemaphore semaphore = Jobs.newExecutionSemaphore(5); (1)
for (int i = 0; i < 100; i++) {
Jobs.schedule(() -> {
// doing something
}, Jobs.newInput()
.withName("job-{}", i)
.withExecutionSemaphore(semaphore)); (2)
}| 1 | Create the execution semaphore initialized with 5 permits |
| 2 | Set the execution semaphore to the job subject for limited concurrency |
Jobs.getJobManager().cancel(Jobs.newFutureFilterBuilder()
.andMatch(new SessionFutureFilter(ISession.CURRENT.get()))
.toFilter(), true);public class CancellableWork implements IRunnable {
@Override
public void run() throws Exception {
// do first chunk of operations
if (RunMonitor.CURRENT.get().isCancelled()) {
return;
}
// do next chunk of operations
if (RunMonitor.CURRENT.get().isCancelled()) {
return;
}
// do next chunk of operations
}
}// Create a blocking condition.
final IBlockingCondition operationCompleted = Jobs.newBlockingCondition(true);
// Schedule a long running operation.
IFuture<Void> future = Jobs.schedule(new LongRunningOperation(), Jobs.newInput());
// Register done callback to unblock the condition.
future.whenDone(event -> {
// Let the waiting job re-acquire a permit and continue execution.
operationCompleted.setBlocking(false);
}, null);
// Wait until done. Thereby, the permit of the current job is released for the time while waiting.
operationCompleted.waitFor();10. RunContext
Mostly, code is run on behalf of some semantic context, for example as a particular Subject and with some context related ThreadLocals set, e.g. the user’s session and its Locale. Scout provides you with different RunContexts, such as ClientRunContext or ServerRunContext. They all share some common characteristics like Subject, Locale and RunMonitor, but also provide some additional functionality like transaction boundaries if using ServerRunContext. Also, a RunContext facilitates propagation of state among different threads. In order to ease readability, the 'setter-methods' of the RunContext support method chaining.
All a RunContext does is to provide some setter methods to construct the context, and a run and call method to run an action on behalf of that context. Thereby, the only difference among those two methods is their argument. Whereas run takes a IRunnable instance, call takes a Callable to additionally return a result to the caller. The action is run in the current thread, meaning that the caller is blocked until completion.
By default, a RunContext is associated with a RunMonitor, and the monitor’s cancellation status can be queried via RunMonitor.CURRENT.get().isCancelled(). The monitor allows for hard cancellation, meaning that the executing thread is interrupted upon cancellation. For instance if waiting on an interruptible construct like Object.wait() or IFuture.awaitDone(), the waiting thread returns with an interruption exception.
10.1. Factory methods to create a RunContext
Typically, a RunContext is created from a respective factory like RunContexts to create a RunContext, or ServerRunContexts to create a ServerRunContext, or ClientRunContexts to create a ClientRunContext. Internally, the BeanManager is asked to provide a new instance of the RunContext, which allows you to replace the default implementation of a RunContext in an easy way. The factories declare two factory methods: empty() and copyCurrent(). Whereas empty() provides you an empty RunContext, copyCurrent() takes a snapshot of the current calling context and initializes the RunContext accordingly. That is useful if only some few values are to be changed, or, if using ServerRunContext, to run the code on behalf of a new transaction.
The following Listing 56 illustrates the creation of an empty RunContext initialized with a particular Subject and Locale.
RunContextSubject subject = new Subject(); (1)
subject.getPrincipals().add(new SimplePrincipal("john"));
subject.setReadOnly();
(2)
RunContexts.empty()
.withSubject(subject)
.withLocale(Locale.US)
.run(() -> {
// run some code (3)
System.out.println(NlsLocale.CURRENT.get()); // > Locale.US
System.out.println(Subject.getSubject(AccessController.getContext())); // > john
});| 1 | create the Subject to do some work on behalf |
| 2 | Create and initialize the RunContext |
| 3 | This code is run on behalf of the RunContext |
The following Listing 57 illustrates the creation of a 'snapshot' of the current calling RunContext with another Locale set.
RunContextRunContexts.copyCurrent()
.withLocale(Locale.US)
.run(() -> {
// run some code
});An important difference is related to the RunMonitor. By using the copyCurrent() factory method, the context’s monitor is additionally registered as child monitor of the monitor of the current calling context. That way, a cancellation request to the calling context is propagated down to this context as well. Of course, that behavior can be overwritten by providing another monitor yourself.
10.2. Properties of a RunContext
The following properties are declared on a RunContext and are inherited by ServerRunContext and ClientRunContext.
| property | description | accessibility |
|---|---|---|
runMonitor |
Monitor to query the cancellation status of the context. * must not be |
RunMonitor.CURRENT.get() |
subject |
Subject to run the code on behalf |
Subject.getSubject(AccessController.getContext()) |
locale |
Locale to be bound to the Locale |
NlsLocale.CURRENT.get() |
propertyMap |
Properties to be bound to the Property |
PropertyMap.CURRENT.get() |
10.3. Properties of a ServerRunContext
A ServerRunContext controls propagation of server-side state and sets the transaction boundaries, and is a specialization of RunContext.
| property | description | accessibility |
|---|---|---|
session |
Session to be bound to Session |
ISession.CURRENT.get() |
transactionScope |
To control transaction boundaries. By default, a new transaction is started, and committed or rolled back upon completion. * Use |
ITransaction.CURRENT.get() |
transaction |
Sets the transaction to be used to run the runnable. Has only an effect, if transaction scope is set to TransactionScope.REQUIRED or TransactionScope.MANDATORY. Normally, this property should not be set manually. |
ITransaction.CURRENT.get() |
clientNotificationCollector |
To associate the context with the given ClientNotificationCollector, meaning that any code running on behalf of this context has that collector set in ClientNotificationCollector.CURRENT thread-local. |
ClientNotificationCollector.CURRENT.get() |
clientNodeId |
Associates this context with the given 'client node ID', meaning that any code running on behalf of this context has that id set in IClientNodeId.CURRENT thread-local. |
IClientNodeId.CURRENT.get() |
10.4. Properties of a ClientRunContext
A ClientRunContext controls propagation of client-side state, and is a specialization of RunContext.
| property | description | accessibility |
|---|---|---|
session |
Session to be bound to Session |
ISession.CURRENT.get() |
form |
Associates this context with the given |
IForm.CURRENT.get() |
outline |
Associates this context with the given |
IOutline.CURRENT.get() |
desktop |
Associates this context with the given |
IDesktop.CURRENT.get() |
11. RunMonitor
A RunMonitor allows the registration of ICancellable objects, which are cancelled upon cancellation of this monitor. A RunMonitor is associated with every RunContext and IFuture, meaning that executing code can always query its current cancellation status via RunMonitor.CURRENT.get().isCancelled().
A RunMonitor itself is also of the type ICancellable, meaning that it can be registered within another monitor as well. That way, a monitor hierarchy can be created with support of nested cancellation. That is exactly what is done when creating a copy of the current calling context, namely that the new monitor is registered as ICancellable within the monitor of the current calling context. Cancellation only works top-down, and not bottom up, meaning that a parent monitor is not cancelled once a child monitor is cancelled.
When registering a ICancellable and this monitor is already cancelled, the ICancellable is cancelled immediately.
Furthermore, a job’s Future is linked with the job’s RunMonitor, meaning that cancellation requests targeted to the Future are also propagated to the RunMonitor, and vice versa.
The following Figure 3 illustrates the RunMonitor and its associations.
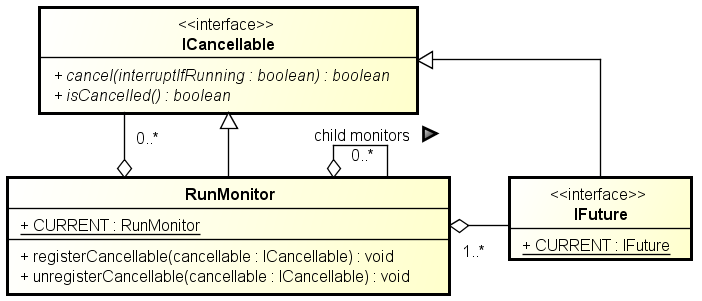
12. Client Notifications
In a scout application, typically, the scout client requests some data from the scout server. Sometimes, however, the communication needs go the other way: The scout server needs to inform the scout client about something. With client notifications it is possible to do so.

12.1. Examples
Example scenarios for client notifications are:
-
some data shared by client and server has changed (e.g. a cache on the client is no longer up-to-date, or a shared variable has changed)
-
a new incoming phone call is available for a specific client and should be shown in the GUI
-
a user wants to send a message to another user
Scout itself uses client notifications to synchronize code type and permission caches and session shared variables.
12.2. Data Flow
A client notification message is just a serializable object. It is published on the server and can be addressed either to all client nodes or only to a specific session or user. On the UI server side, handlers can be used to react upon incoming notifications.
Client notification handlers may change the state of the client model. In case of visible changes in the UI, these changes are automatically reflected in the UI.
In case of multiple server nodes, the client notifications are synchronized using cluster notifications to ensure that all UI servers receive the notifications.
12.3. Push Technology
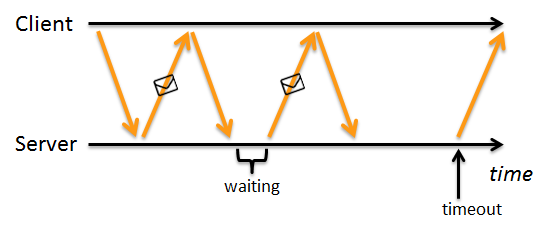
Client notifications are implemented using long polling as described below, because long polling works reliably in most corporate networks with proxy servers between server and client
as well as with security policies that do not allow server push.
With long polling, the client requests notifications from the server repeatedly. If no new notifications are available on the server, instead of sending an empty response, the server holds the request open and waits until new notifications are available or a timeout is reached.
In addition to the long polling mechanism, pending client notifications are also transferred to the client along with the response of regular client requests.
12.4. Components
A client notification can be published on the server using the ClientNotificationRegistry.
Publishing can be done either in a non-transactional or transactional way (only processed, when the transaction is committed).
The UI Server either receives the notifications via the ClientNotificationPoller or in case of transactional notifications
together with the response of a regular service request. The notification is then dispatched to the corresponding handler.
When a client notifications is published on the server, it is automatically synchronized with the other server nodes (by default).
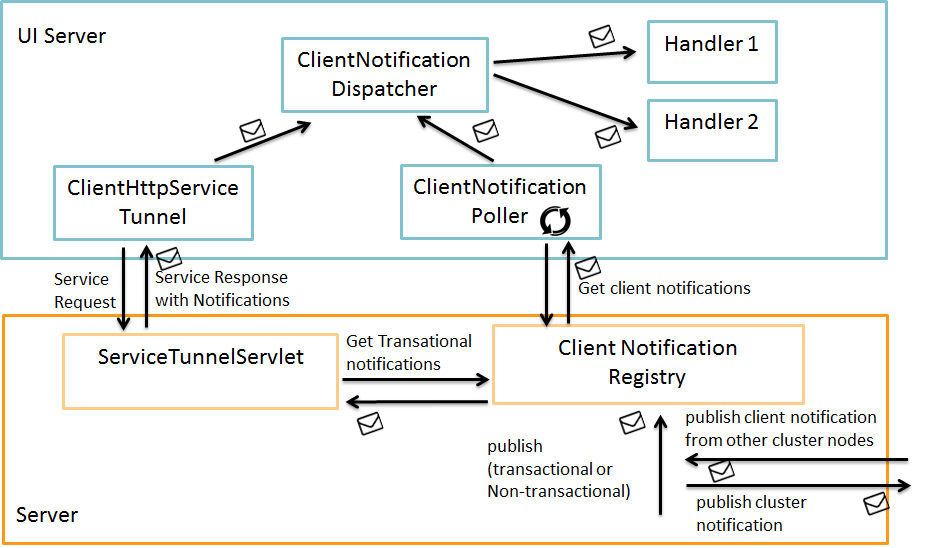
12.4.1. Multiple Server Nodes
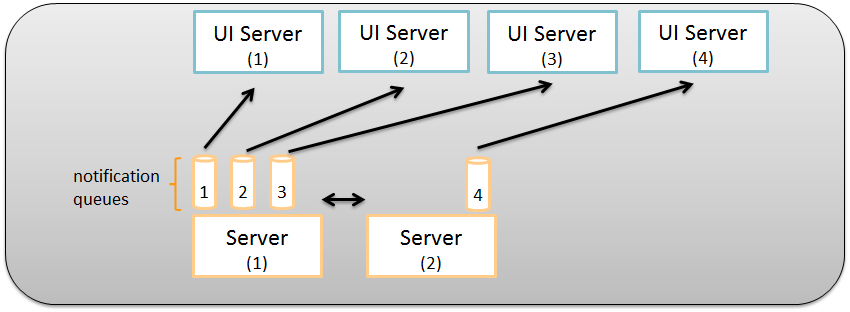
In order to deal with multiple ui-server nodes, the server holds a single notifications queue per ui-server node.
In this queues only the relevant notifications need to be kept: If a client notification is addressed to a session or user, that does not exist on a ui-server node, it is not added to the queue.
Sessions and corresponding users are registered on the server upon creation (and de-registered after destruction).
12.5. Publishing
BEANS.get(ClientNotificationRegistry.class).putForUser("admin", new PersonTableChangedNotification());There are several options to choose from when publishing a new client notification:
12.5.1. ClientNotificationAddress
The ClientNotificationAddress determines which how the client notification needs to be dispatched and handled.
A client notification can be addressed to
-
all nodes
-
all sessions
-
one or more specific session
-
one or more specific user
12.5.2. Transactional vs. Non-transactional
Client notifications can be published in a transactional or non-transactional way.
-
Transactional means that the client notifications are only published once the transaction is committed. If the transaction fails, client notifications are disregarded.
-
Non-transactional means that client notifications are published immediately without considering any transactions.
12.5.3. Distributing to all Cluster Nodes
Generally, it makes sense to distribute the client notifications automatically to all other server cluster nodes (if available). This is achieved using ClusterNotifications.
It is however also possible to publish client notifications without cluster distribution. E.g. in case of client notifications already received from other cluster nodes.
12.5.4. Coalescing Notifications
It is possible that a service generates a lot of client notifications that are obsolete once a newer notification is created. In this case a coalescer can be created to reduce the notifications:
public class BookmarkNotificationCoalescer implements ICoalescer<BookmarkChangedClientNotification> {
@Override
public List<BookmarkChangedClientNotification> coalesce(List<BookmarkChangedClientNotification> notifications) {
// reduce to one
return CollectionUtility.arrayList(CollectionUtility.firstElement(notifications));
}
}12.6. Handling
The ClientNotificationDispatcher is responsible for dispatching the client notifications to the correct handler.
12.6.1. Creating a Client Notification Handler
To create a new client notification handler for a specific client notification, all you need to do is creating a class implementing
org.eclipse.scout.rt.shared.notification.INotificationHandler<T>, where T is the type (or subtype) of the notification to handle.
The new handler does not need to be registered anywhere. It is available via jandex class inventory.
MessageNotificationspublic class MessageNotificationHandler implements INotificationHandler<MessageNotification> {
@Override
public void handleNotification(final MessageNotification notification) {12.6.2. Handling Notifications Temporarily
Sometimes it is necessary to start and stop handling notification dynamically, (e.g. when a form is opened) in this case AbstractObservableNotificationHandler
can be used to add and remove listeners.
12.6.3. Asynchronous Dispatching
Dispatching is always done asynchronously. However, in case of transactional notifications, a service call blocks until all transactional notifications returned with the service response are handled.
This behavior was implemented to simplify for example the usage of shared caches:
CodeService cs = BEANS.get(CodeService.class);
cs.reloadCodeType(UiThemeCodeType.class);
//client-side reload triggered by client notifications is finished
List<? extends ICode<String>> reloadedCodes = cs.getCodeType(UiThemeCodeType.class).getCodes();In the example above, it is guaranteed, that the codetype is up-to-date as soon as reloadCodeType is finished.
12.6.4. Updating Scout Model
Notification handlers are never called from a scout model thread. If the scout model needs to be updated when handling notifications, a model job needs to be created for that task.
@Override
public void handleNotification(final MessageNotification notification) {
ModelJobs.schedule(() -> {
UserNodePage userPage = getUserNodePage();
String buddy = notification.getSenderName();
if (userPage != null) {
ChatForm form = userPage.getChatForm(buddy);
if (form != null) {
form.getHistoryField().addMessage(false, buddy, form.getUserName(), new Date(), notification.getMessage());
}
}
}, ModelJobs.newInput(ClientRunContexts.copyCurrent()));
}| Make sure to always run updates to the scout models in a model job (forms, pages, …): Use ModelJobs.schedule(…) where necessary in notification handlers. |
13. Extensibility
| Required version: The API described here requires Scout version 4.2 or newer. |
13.1. Overview
Since December 2014 and Scout 4.2 or newer a new extensibility concept is available for Scout. This article explains the new features and gives some examples how to use them.
When working with large business applications it is often required to split the application into several modules. Some of those modules may be very basic and can be reused in multiple applications. For those it makes sense to provide them as binary library. But what if you have created great templates for your applications but in one special case you want to include one more column in a table or want to execute some other code when a pre-defined context menu is pressed? You cannot just modify the code because it is a general library used everywhere. This is where the new extensibility concept helps.
To achieve this two new elements have been introduced:
-
Extension Classes: Contains modifications for a target class. Modifications can be new elements or changed behavior of existing elements.
-
Extension Registry: Service holding all Extensions that should be active in the application.
The Scout extensibility concept offers three basic possibilites to extend existing components:
-
Extensions Changing behavior of a class
-
Contributions Add new elements to a class
-
Moves Move existing elements within a class
The following chapers will introduce this concepts and present some examples.
13.2. Extensions
Extensions contain modifications to a target class. This target class must be extensible. All elements that implement org.eclipse.scout.rt.shared.extension.IExtensibleObject are extensible. And for all extensible elements there exists a corresponding abstract extension class.
Examples:
-
AbstractStringFieldis extensible. Therefore there is a classAbstractStringFieldExtension. -
AbstractCodeTypeis extensible. Therefore there is a classAbstractCodeTypeExtension.
Target classes can be all that are instanceof those extensible elements. This means an AbstractStringFieldExtension can be applied to AbstractStringField and all child classes.
Extensions contain methods for all Scout Operations (see Exec Methods). Those methods have the same signature except that they have one more input parameter. This method allows you to intercept the given Scout Operation and execute your own code even though the declaring class exists in a binary library. It is then your decision if you call the original code or completely replace it. To achieve this the Chain Pattern is used: All extensions for a target class are called as part of a chain. The order is given by the order in which the extensions are registered. And the original method of the Scout element is an extension as well.
Extensions to specific types of elements are prepared as abstract classes:
-
AbstractGroupBoxExtension
-
AbstractImageFieldExtension
The following image visualizes the extension chain used to intercept the default behavior of a component:
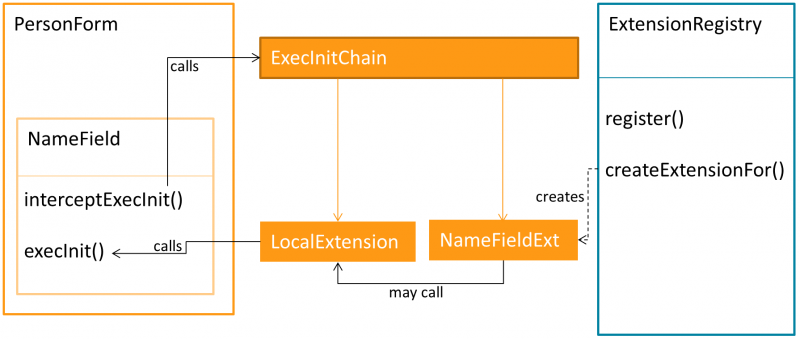
13.2.1. Extending a StringField example
The following example changes the initial value of a StringField called NameField:
public class NameFieldExtension extends AbstractStringFieldExtension<NameField> {
public NameFieldExtension(NameField owner) {
super(owner);
}
@Override
public void execInitField(FormFieldInitFieldChain chain) {
chain.execInitField(); // call the original exec init. whatever it may do.
getOwner().setValue("FirstName LastName"); // overwrite the initial value of the name field
}
}Note: The type parameter of the extension (e.g. NameField) denotes the element which is extended.
The extension needs to be registeres when starting the application:
Jobs.schedule(() -> BEANS.get(IExtensionRegistry.class).register(NameFieldExtension.class), Jobs.newInput()
.withRunContext(ClientRunContexts.copyCurrent())
.withName("register extension"));13.3. Contributions
The section before explained how to modify the behavior of existing Scout elements. This section will describe how to contribute new elements into existing containers.
This is done by using the same mechanism as before. It is required to create an Extension too. But instead of overwriting any Scout Operation we directly define the new elements within the Extension. A lot of new elements can be added this way: Fields, Menus, Columns, Codes, …
Some new elements may also require a new DTO (FormData, TablePageData, TableData) to be filled with data from the server. The corresponding DTO for the extension is automatically created when using the SDK 4.2 or newer and having the @Data annotation specified on your extension. As soon as the DTO extension has been registered in the IExtensionRegistry service it is automatically created when the target DTO is created and will also be imported and exported automatically!
The following example adds two new fields for salary and birthday to a PersonForm. Please note the @Data annotation which describes where the DTO for this extension should be created.
/**
* Extension for the MainBox of the PersonForm
*/
@Data(PersonFormMainBoxExtensionData.class)
public class PersonFormMainBoxExtension extends AbstractGroupBoxExtension<MainBox> {
public PersonFormMainBoxExtension(MainBox ownerBox) {
super(ownerBox);
}
@Order(2000)
public class SalaryField extends AbstractBigDecimalField {
}
@Order(3000)
public class BirthdayField extends AbstractDateField {
}
}The extension data must be registered manually in the job like in the example before:
BEANS.get(IExtensionRegistry.class).register(PersonFormMainBoxExtension.class);Then the SDK automatically creates the extension DTO which could look as follows. Please note: The DTO is generated automatically but you have to register the generated DTO manually!
/**
* <b>NOTE:</b><br>
* This class is auto generated by the Scout SDK. No manual modifications recommended.
*/
@Extends(PersonFormData.class)
@Generated(value = "org.eclipse.scout.docs.snippets.person.PersonFormMainBoxExtension", comments = "This class is auto generated by the Scout SDK. No manual modifications recommended.")
public class PersonFormMainBoxExtensionData extends AbstractFormFieldData {
private static final long serialVersionUID = 1L;
public Birthday getBirthday() {
return getFieldByClass(Birthday.class);
}
public Salary getSalary() {
return getFieldByClass(Salary.class);
}
public static class Birthday extends AbstractValueFieldData<Date> {
private static final long serialVersionUID = 1L;
}
public static class Salary extends AbstractValueFieldData<BigDecimal> {
private static final long serialVersionUID = 1L;
}
}You can also access the values of the DTO extension as follows:
// create a normal FormData
// contributions are added/imported/exported automatically
PersonFormData data = new PersonFormData();
// access the data of an extension
PersonFormMainBoxExtensionData c = data.getContribution(PersonFormMainBoxExtensionData.class);
c.getSalary().setValue(new BigDecimal("200.0"));13.3.1. Extending a form and a handler
Extending a AbstractForm and one (or more) of its AbstractFormHandlers that can be achieved as follows:
public class PersonFormExtension extends AbstractFormExtension<PersonForm> {
public PersonFormExtension(PersonForm ownerForm) {
super(ownerForm);
}
@Override
public void execInitForm(FormInitFormChain chain) {
chain.execInitForm();
// Example logic: Access the form, disable field
getOwner().getNameField().setEnabled(false, true, true);
}
public void testMethod() {
MessageBoxes.create().withHeader("Extension method test").withBody("A method from the form extension was called").show();
}
public static class NewFormHandlerExtension extends AbstractFormHandlerExtension<NewHandler> {
public NewFormHandlerExtension(NewHandler owner) {
super(owner);
}
@Override
public void execPostLoad(FormHandlerPostLoadChain chain) {
chain.execPostLoad();
// Example logic: Show a message box after load
MessageBoxes.create().withHeader("Extension test").withBody("If you can read this, the extension works correctly").show();
// Access element from the outer extension.
PersonFormExtension extension = ((AbstractForm) getOwner().getForm()).getExtension(PersonFormExtension.class);
extension.testMethod();
}
}
}There are a few things to note about this example:
-
It is only necessary to register the outer form extension, not the inner handler extension as well.
-
The inner handler extension must be
static, otherwise an Exception will occur when the extended form is being started! -
You can access the element you are extending by calling
getOwner(). -
Since you cannot access elements from your form extension directly from the inner handler extension (because it is static), you will need to retrieve the form extension via the
getExtension(Class<T extends IExtension<?>>)method on the extended object, as done here to retrieve the form extension from the form handler extension.
13.4. Move elements
You can also move existing Scout elements to other positions. For this you have to register a move command in the IExtensionRegistry. As with all extension registration it is added to the extension registration Job in your Activator class:
BEANS.get(IExtensionRegistry.class).registerMove(NameField.class, 20d, LastBox.class);13.5. Migration
The new extensibility concept is added on top of all existing extension possibilities like injection or sub-classing. Therefore it works together with the current mechanisms. But for some use cases (like modifying template classes) it offers a lot of benefits. Therefore no migration is necessary. The concepts do exist alongside each others.
However there is one impact: Because the Scout Operation methods are now part of a call chain they may no longer be invoked directly. So any call to e.g. execValidateValue() is no longer allowed because this would exclude the extensions for this call. The Scout SDK marks such calls with error markers in the Eclipse Problems view. If really required the corresponding intercept-Method can be used. So instead directly calling myField.execChangedValue you may call myField.interceptChangedValue().
14. Mobile Support
Scout applications are mobile capable, meaning that they can be used on portable touch devices like smart phones and tablets. This capability is based on 2 main parts:
-
Responsive and Touch Capable Widgets
-
Device Transformation
14.1. Responsive and Touch Capable Widgets
Responsive design in context of a web application means that the design reacts to screen size changes. A Scout application does not use responsive design for the whole page, but many widgets itself may change the appearance when they don’t fit into screen.
One example is the menu bar that stacks all menus which don’t fit into an ellipsis menu.

Beside being responsive, the widgets may deal with touch devices as well. This means they are big enough to be used with the finger. And they don’t need a mouse, especially the right mouse button.
One example is the tooltip of a form field which is reflected by an info icon on the right side of the field. Instead of hovering over the field the user can press that info icon to bring up the tooltip. This approach not only provides an indicator where tooltips are available, it also works for mouse and touch based devices.

14.1.1. GroupBox
Another widget that will react to changing sizes is the group box. Once a group box becomes smaller than its preferred width it will transform its internal fields. Example: For all internal fields the labelPosition will be set to 'top' to give the field more horizontal space.

Those transformations are handled by scout.GroupBoxResponsiveHandler and managed by scout.ResponsiveManager. The manager decides when to switch to a responsive mode and back. If desired, the responsive transformations can be completely disabled by calling scout.responsiveManager.setActive(false).
By default all the main boxes will be responsive. In order to exclude a group box from the responsive transformations you could do the following:
@Order(20)
public class MyGroupBox extends AbstractGroupBox {
@Override
protected TriState getConfiguredResponsive() {
return TriState.parse(false);
}
}The handler is called when the manager detects a changed responsive state to perform its transformations. There are three responsive modes, of which only the first two are supported in scout classic.
-
Normal (e.g. width >= 500): Regular case, no transformations are applied.
-
Condensed (e.g. 300 ⇐ width < 500): Sets the label position to 'TOP'.
-
Compact (e.g. width < 300): This mode is only supported in scout js. Sets grid column count to 1 and ensures labels and status are set to 'TOP'.
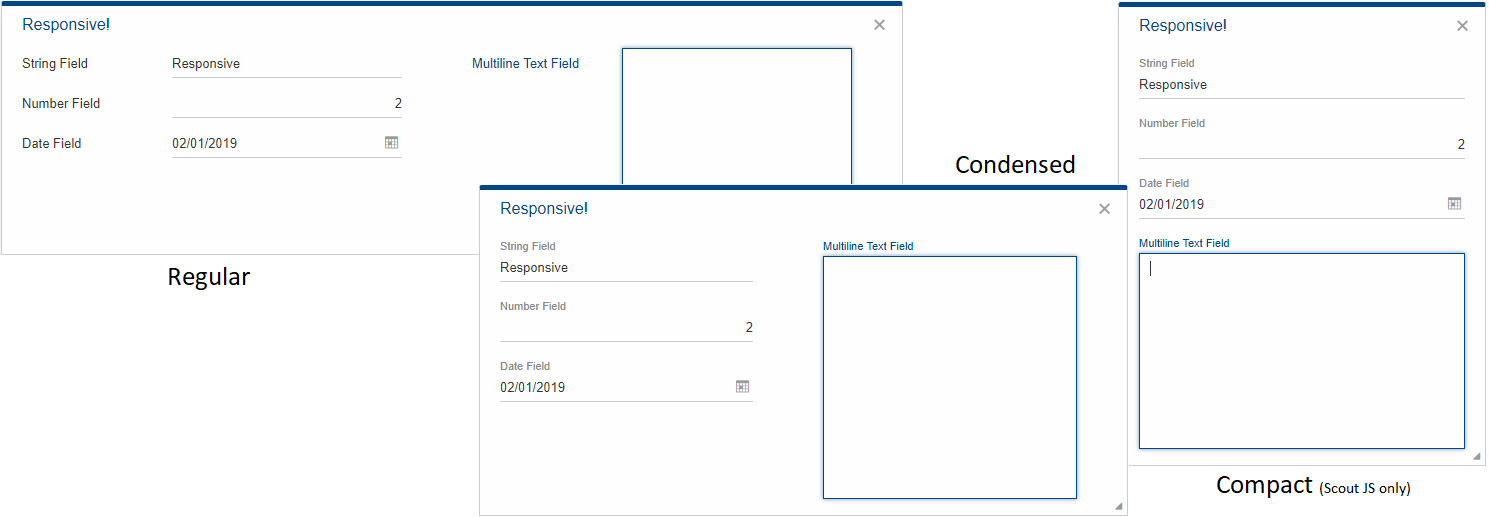
Add a Custom Handler
If a different widget is required to react to screen size changes, you can create your own handler by subclassing scout.ResponsiveHandler and registering it by calling scout.responsiveManager.register(widget, handler). Each handler can define the thresholds when to switch from one responsive mode to another by implementing scout.ResponsiveHandler.prototype.getCompactThreshold or scout.ResponsiveHandler.prototype.getCondensedThreshold.
14.2. Device Transformation
The second part of the mobile support is called device transformation. Transformation means the adaptation of model properties for different devices. Example: Setting the property labelPosition from 'left' to 'top' in order to move the label to the top.
Such transformations are done on the UI server by so called device transformers. Currently 3 device transformers are available:
-
Mobile Device Transformer
-
Tablet Device Transformer
-
Touch Device Transformer
Which transformer is active depends on the used user agent. The mobile transformer is active if the Scout app is used on a smart phone, the tablet one is active if it is used from a tablet, and the touch transformer is active in both cases. And may also be active if a desktop device supports touch.
The order in which these transformers are processed is defined using the @Order annotation which is possible because they are regular Scout beans. This also means you can add your own transformer if you need custom transformations.
The transformations are mainly limited to the adjustment of properties, although some properties have a bigger effect than others. The property displayStyle of the desktop for example controls the look of the desktop and setting it to COMPACT rearranges the desktop in a mobile friendly way.

All the transformations are triggered by extensions to components like form fields or the desktop. These extensions are registered by DeviceTransformationPlatformListener. If you don’t want any of these transformers to be active you could simply replace this listener and do nothing.
14.3. Adapt specific Components
The device transformers take care of global transformations which should be applied for most of the components. If you need to adapt a specific component you can do it at the component itself. Let’s say you want to hide a field if the application is running on a smart phone, you could do the following.
@Order(20)
public class MyField extends AbstractStringField {
@Override
protected void execInitField() {
if (UserAgentUtility.isMobileDevice()) {
setVisibleGranted(false);
}
}
}14.4. User Agent
The class UserAgent is essential for the mobile support. It stores information about the running device like the used browser or OS. The user agent is available on the UI server as well as on the backend server and can be accessed using the static method UserAgent.get().
The class UserAgentUtility provides some useful helper methods to check which type of device is running, like if it’s a mobile phone, a tablet, or a desktop device.
14.5. Best Practices
When creating a Scout application which should run on touch devices as well, the following tipps may help you.
-
Focus on the essential. Even though most of the application should run fine on a mobile device, some parts may not make sense. Identify those parts and make them invisible using
setVisibleGranted(false). The advantage of using setVisibleGranted over setVisible is that the model of the invisible components won’t be sent to the client at all, which might increase the performance a little. But remember: The users nowadays might expect every functionality to be available even on a mobile phone, so don’t take them away too much. -
Limit the usage of custom HTML. Custom HTML cannot be automatically transformed, so you need to do it by yourself. Example: You created a table with several columns using HTML. On a small screen this table will be too large, so you have to make sure that your table is responsive, or provide other HTML code when running on a mobile device.
-
Don’t use too large values for gridH. GridH actually is the minimum grid height, so if you set gridH to 10 the field will always be at least 10 logical grid rows height. This may be too big on a mobile device.
-
Use appropriate values for table column width. Tables are displayed the same way on a mobile phone as on the desktop device, if the content is not fully visible the user can scroll. If you have tables with
autoResizeColumnsset to true, you should make sure that the column widths are set properly. Just check how the table looks on a small screen and adjust the values accordingly. -
Know the difference between small screens and touch capable. If you do checks against different device types, you should be aware that a touch device is not necessarily a small device. That means
UserAgentUtility.isTouchDevice()may be true on a laptop as well, so use it with care. -
If you use filler fields for layouting purpose, make sure you use the official
IPlaceholderField. Such filler fields normally waste space on a one column layout, so the mobile transformer will make them invisible.
15. Security
15.1. Default HTTP Response Headers
All Scout HTTP servlets delegate to a central authority to append HTTP response headers. This is the bean HttpServletControl.
It enables developers to control which headers that should be added to the HTTP response for each servlet and request.
The next sections describe the headers that are added to any response by default. Beside these also the following headers may be of interest for an end user application (consider adding them to your application if possible):
| Please note that not all headers are supported in all user agents! |
15.1.1. X-Frame-Options
The X-Frame-Options HTTP response header [3] can be used to indicate whether or not a user agent should be allowed to render a page in a <frame>, <iframe> or <object>.
Sites can use this to avoid clickjacking [4] attacks, by ensuring that their content is not embedded into other sites.
The X-Frame-Options header is described in RFC 7034 [5].
In Scout this header is set to SAMEORIGIN which allows the page to be displayed in a frame on the same origin (scheme, host and port) as the page itself only.
15.1.2. X-XSS-Protection
This header enables the XSS [6] filter built into most recent user agents. It’s usually enabled by default anyway, so the role of this header is to re-enable the filter for the website if it was disabled by the user. The X-XSS-Protection header is described in controlling-the-xss-filter.
In Scout this header is configured to enable XSS protections and instructs the user-agent to block a page from loading if reflected XSS is detected.
15.1.3. Content Security Policy
Content Security Policy is a HTTP response header that helps you reduce XSS risks on modern user agents by declaring what dynamic resources are allowed to load [7]. The CSP header is described in Level 1 and Level 2. There is also a working draft for a Level 3.
Scout makes use of Level 1 (and one directive from Level 2) and sets by default the following settings:
-
JavaScript [8]: Only accepts JavaScript resources from the same origin (same scheme, host and port). Inline JavaScript is allowed and unsafe dynamic code evaluation (like
eval(string),setTimeout(string),setInterval(string),new Function(string)) is allowed as well. -
Stylesheets (CSS) [9]: Only accepts Stylesheet resources from the same origin (same scheme, host and port). Inline style attributes are allowed.
-
Frames [10]: All sources are allowed because the iframes created by the Scout BrowserField run in the sandbox mode and therefore handle the security policy on their own.
-
All other types (Image,
WebSocket[11],EventSource[12], AJAX calls [13], fonts,<object>[14],<embed>[15],<applet>[16],<audio>[17] and<video>[18]) only allow resources from the same origin (same scheme, host and port).
If a resource is blocked because it violates the CSP a report is created and logged on server side using level warning. This is done in the class ContentSecurityPolicyReportHandler.
This enables admins to monitor the application and to react if a CSP violation is detected.
15.2. Session Cookie (JSESSIONID Cookie) Configuration Validation
The UiServlet checks if the session cookie is configured safely. The validation is only performed on first access to the UiServlet. There is no automatic validation on the backend server side or on any custom servlets!
If the validation fails, a corresponding error message is logged to the server and an exception is thrown making the UiServlet inaccessible. Because of security reasons the exception shown to the user includes no details about the error. These can only be seen on the server side log.
15.2.1. HttpOnly
First the existence of the HttpOnly flag is checked. The servlet container will then add this flag to the Set-Cookie HTTP response header. If the user agent supports this flag, the cookie cannot be accessed through a client side script. As a result even if a cross-site scripting (XSS) flaw exists and a user accidentally accesses a link that exploits this flaw, the user agent will not reveal the cookie to a third party.
For a list of user agents supporting this feature please refer to OWASP.
It is recommended to always enable this flag.
Since Java Servlet 3.0 specification this property can be set in the configuration in the deployment descriptor WEB-INF/web.xml:
<?xml version="1.0" encoding="UTF-8"?>
<web-app
xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
version="3.1">
...
<session-config>
...
<cookie-config>
<http-only>true</http-only> (1)
...
</cookie-config>
...
</session-config>
...
</web-app>| 1 | The HttpOnly flag activated |
15.2.2. Secure
Second the existence of the Secure flag is checked. The servlet container will then add this flag to the Set-Cookie HTTP response header. The purpose of the secure flag is to prevent cookies from being observed by unauthorized parties due to the transmission of a the cookie in clear text. Therefore setting this flag will prevent the user agent from transmitting the session id over an unencrypted channel.
Since Java Servlet 3.0 specification this property can be set in the configuration in the deployment descriptor WEB-INF/web.xml:
<?xml version="1.0" encoding="UTF-8"?>
<web-app
xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
version="3.1">
...
<session-config>
...
<cookie-config>
<secure>true</secure> (1)
...
</cookie-config>
...
</session-config>
...
</web-app>| 1 | The Secure flag activated |
This of course only makes sense if the application is exposed to the end user using an encrypted channel like HTTPS (which is strongly recommended).
Unfortunately for the UI server it is not possible to detect if an application uses a secured channel. Consider the following example: The servlet container is protected by a reverse proxy. The communication between the user agent and the proxy is encrypted while the channel between the proxy and the servlet container is not. In this scenario the container cannot know that from a user agent point of view the channel is secured.
Because of this the validation assumes that the channel from the user agent to the entering node is secured and by default checks for the Secure flag. In case this assumption is not true and an unencrypted channel must be used this validation step can be disabled by setting the following property in the config.propertis file:
scout.auth.cookieSessionValidateSecure=false
This skips the Secure flag check completely. In this scenario (not using https) it is also required to remove the secure tag from the cookie config in the WEB-INF/web.xml.
15.3. Secure Output
This chapter describes how HTML Output can be handled in a secure way.
Scout applications often display potentially dangerous data, e.g. user input or data from other systems. Encoding this input in such a way, that it can not be executed, prevents security vulnerabilities like cross-site scripting.
15.3.1. Encoding by Default
By default, all input in the Scout model is encoded. Examples are values/labels in value fields, cells in tables, message in message box. The reason behind this default choice is that developers do not have to think about output encoding in the standard case and are therefore less likely to forget output encoding and introduce a security vulnerability.
Example: In the following label field, the HTML <b> tag is encoded as <b>bold text</b>:

public class LabelField extends AbstractLabelField {
@Override
protected void execInitField() {
setValue("...<b>Bold text</b>...");
}
15.3.2. Html Enabled
Sometimes developers may want to use HTML in the Scout model.
Examples are
-
Simple styling of dynamic content, such as addresses or texts in message boxes
-
Text containing application-internal or external links
-
Html or XML content received from other systems, such as e-mails or html pages
Html input should only partially be encoded or not at all.
To disable the encoding of the whole value, the property HtmlEnabled can be used:
public class NoEncodingLabelField extends AbstractLabelField {
@Override
protected boolean getConfiguredHtmlEnabled() {
return true;
}
@Override
protected void execInitField() {
setValue("...<b>Bold text</b>...");
}
There are several ways to implement the use cases above. Some typical implementations are described in the following sections.
CSS Class and Other Model Properties
Often using HTML in value fields or table cells is not necessary for styling. Very basic styling can be done for example by setting the CSS class.
HTML Builder
For creating simple HTML files or fragments with encoded user input, the class org.eclipse.scout.rt.platform.html.HTML can be used. It is also easily possible to create application internal and external link with this approach.
Styling in the UI-Layer
For more complex HTML, using IBeanField in the scout model and implementing the styling in the UI-Layer is often the preferred way.
Links are possible as well.
Manual Encoding
It is also possible to encode any String manually using StringUtility.htmlEncode(String). org.eclipse.scout.rt.platform.html.HTML uses this method internally for encoding.
However, using HTML is recommended, where possible, because it is more concise and leads to less errors.
Using a White-List Filter
If HTML or XML from external sources or more complex HTML are used in the Scout model, using a white-list filter might be the best way to avoid security bugs. Libraries, such as JSoup provide such a white-list filter. Scout currently does not include any services or utilities for using white-list filters, because the configuration and usage is very use-case-specific and would therefore not add much benefit.
16. Data Objects
Data objects are Scout beans, which are used as data transfer objects for synchronous REST and asynchronous MOM interfaces. Furthermore, they can be used as domain objects within business logic.
16.1. Data Object Definition
A data object extends the DoEntity base class and declares each attribute as a single accessor method.
Attributes of two kinds are available:
-
Value attribute of type
T -
List attribute of type
List<T>
The name of the accessor method defines the attribute name. The return value of the accessor method defines the attribute type.
@TypeName("ExampleEntity")
@TypeVersion("scout-8.0.0.027")
public class ExampleEntityDo extends DoEntity {
public DoValue<String> name() { (1)
return doValue("name");
}
public DoList<Integer> values() { (2)
return doList("values");
}| 1 | Example attribute of type String |
| 2 | Example attribute of type List<Integer> |
For convenience reasons when working with the data objects it is recommended to add a getter and a with (e.g. setter) method. Using the convenience with methods, new data objects can be created with fluent-style API:
ExampleEntityDo entity = BEANS.get(ExampleEntityDo.class)
.withName("Example")
.withValues(1, 2, 3, 4, 5);16.2. Marshalling
Using the IDataObjectMapper interface a data object can be converted from and to its string representation.
The marshalling strategy is generic and replaceable.
The Scout platform defines the IDataObjectMapper interface, at runtime a Scout bean implementing the interface must be available.
The Scout module org.eclipse.scout.rt.jackson provides a default implementation serializing data objects from and to JSON using the Jackson library.
String string = BEANS.get(IDataObjectMapper.class).writeValue(entity);The data object ExampleEntityDo serialized to JSON:
{
"_type" : "ExampleEntity",
"name" : "example",
"values" : [1,2,3,4,5]
} ExampleEntityDo marhalled = BEANS.get(IDataObjectMapper.class)
.readValue(string, ExampleEntityDo.class);16.2.1. Type Name
A data object is annotated with a logical type name using the @TypeName annotation.
The annotation value is added to the serialized JSON object as top-level _type property.
Using the type property the data object marshaller is able to find and instantiate the matching data object class, without having to rely on a fully classified class name.
If no @TypeName annotation is declared for a data object class, the simple class name is used as default value for the _type attribute.
| Declaring a logical type name using the `@TypeName`annotation is highly recommended to avoid a 1:1 dependency between the serialized JSON String and the fully classified class name. A stable type name is required in order to be able to change the data object structure without breaking the API. |
16.2.2. Type Version
A data object may be annotated with a type version using the @TypeVersion annotation.
The type version represents the version of the structure of the data object and not the version of the data within the data object.
The type version value should be incremented, each time, the data object class is modified (add/remove/rename attributes).
If a version is required for versioning the values of a data object, consider add a version attribute, incrementing its value, every time a value of the data object is modified.
The annotation value is added to the serialized JSON object as top-level _typeVersion property.
The serialized _typeVersion value is not deserialized into an attribute, since the deserializer creates a concrete data object class at runtime, having the @TypeVersion annotation providing the type version value.
| Declaring a logical type version using the `@TypeVersion`annotation is highly recommended if a data object is persisted as JSON document to a file or database. |
16.2.3. Data Object Naming Convention
Scout objects use the following naming conventions:
-
A data object class should use the `Do' suffix.
-
The value of the
@TypeNameannotation corresponds to the simple class name withoutDosuffix
16.2.4. Attribute Name
The default attribute name within the serialized string corresponds to the name of the attribute accessor method defined in the data object.
To use a custom attribute name within the serialized string, the attribute accessor method can be annotated by @AttributeName providing the custom attribute name.
@AttributeName("myCustomName")
public DoValue<String> name() {
return doValue("myCustomName"); (1)
}| 1 | Important: The annotation value must be equals to the string constant used for the doValue() or doList() attribute declaration. |
{
"_type" : "CustomAttributeNameEntity",
"myCustomName" : "example"
}16.2.5. Attribute Format
Using the ValueFormat annotation a data type dependent format string may be provided, which is used for the marshalling.
@ValueFormat(pattern = IValueFormatConstants.DATE_PATTERN)
public DoValue<Date> date() {
return doValue("date");
}The IValueFormatConstants interface declares a set of default format pattern constants.
Attributes with type java.util.Date accept the format pattern specified by SimpleDateFormat class (see https://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html)
16.3. Ignoring an Attribute
The @JsonIgnore annotation included in the Jackson library is currently not supported for data objects.
To ignore an attribute when serializing a data object, the attribute must be removed from the data object by either not setting a value for the desired attribute
or by explicitly removing the attribute before a data object is serialized:
ExampleEntityDo entity = BEANS.get(ExampleEntityDo.class)
.withName("Example")
.withValues(1, 2, 3, 4, 5);
// remove by attribute accessor method reference
entity.remove(entity::name);
// remove by attribute node
entity.remove(entity.name());
// remove by attribute name
entity.remove(entity.name().getAttributeName());
// remove by attribute name raw
entity.remove("name");16.4. Handling of DoEntity Attributes
Instead of data objects, a REST or MOM interface could be built using simple plain old Java objects (POJOs). Compared to POJOs a Scout data object offers additional support and convenience when working with attributes.
A JSON attribute may have three different states:
-
Attribute available with a value
-
Attribute available with value
null -
Attribute not available
These three states cannot be represented with a POJO object which is based on a single variable with a pair of getter/setter.
In order to differ between value not available and value is null, a wrapper type is required, which beside the value stores the information, if the attribute is available.
Scout data objects solve this issue: Data objects internally use a Map<String, DoNode<?>> where the abstract DoNode at runtime is represented by a DoValue<T> or a DoList<T> object instance wrapping the value.
16.4.1. Access Data Object Attributes
-
Value:
DoNode.get()returns the (wrapped) value of the attribute
ExampleEntityDo entity = BEANS.get(ExampleEntityDo.class)
.withName("Example")
.withValues(1, 2, 3, 4, 5);
// access using attribute accessor
String name1 = entity.name().get();
List<Integer> values1 = entity.values().get();
// access using generated attribute getter
String name2 = entity.getName();
List<Integer> values2 = entity.getValues();-
Existence: Using the
DoNode.exists()method, each attribute may be checked for existence
// check existence of attribute
boolean hasName = entity.name().exists();16.5. Abstract Data Objects & Polymorphism
A simple data objects is implemented by subclassing the DoEntity class.
For a complex hierarchy of data objects the base class may be abstract and extend the DoEntity class, further subclasses extend the abstract base class.
The abstract base data object class does not need to specify a @TypeName annotation since there are no instances of the abstract class which are serialized or deserialized directly.
Each non-abstract subclass must specify a unique @TypeName annotation value.
public abstract class AbstractExampleEntityDo extends DoEntity {
public DoValue<String> name() {
return doValue("name");
}@TypeName("ExampleEntity1")
public class ExampleEntity1Do extends AbstractExampleEntityDo {
public DoValue<String> name1Ex() {
return doValue("name1Ex");
}@TypeName("ExampleEntity2")
public class ExampleEntity2Do extends AbstractExampleEntityDo {
public DoValue<String> name2Ex() {
return doValue("name2Ex");
}public class ExampleDoEntityListDo extends DoEntity {
public DoList<AbstractExampleEntityDo> listAttribute() {
return doList("listAttribute");
}
public DoValue<AbstractExampleEntityDo> singleAttribute() {
return doValue("singleAttribute");
} ExampleDoEntityListDo entity = BEANS.get(ExampleDoEntityListDo.class);
entity.withListAttribute(
BEANS.get(ExampleEntity1Do.class)
.withName1Ex("one-ex")
.withName("one"),
BEANS.get(ExampleEntity2Do.class)
.withName2Ex("two-ex")
.withName("two"));
entity.withSingleAttribute(
BEANS.get(ExampleEntity1Do.class)
.withName1Ex("single-one-ex")
.withName("single-one"));If an instance of ExampleDoEntityListDo is serialized, each attribute is serialized using its runtime data type, adding an appropriate _type attribute to each serialized object.
Therefore, the deserializer knows which concrete class to instantiate while deserializing the JSON document.
This mechanism is used for simple value properties and list value properties.
To each object which is part of a list value property the _type property is added to support polymorphism within single elements of a list.
{
"_type" : "ExampleDoEntityListDo",
"listAttribute" : [ {
"_type" : "ExampleEntity1",
"name" : "one",
"name1Ex" : "one-ex"
}, {
"_type" : "ExampleEntity2",
"name" : "two",
"name2Ex" : "two-ex"
} ],
"singleAttribute" : {
"_type" : "ExampleEntity1",
"name" : "single-one",
"name1Ex" : "single-one-ex"
}
}16.6. Rename an attribute of a data object in a subclass
To rename a data object attribute in a subclass, override the attribute accessor method and annotate it with @AttributeName using the new attribute name as value.
Additionally the overridden method must call the doValue() method providing the new attribute name as argument.
@TypeName("ExampleEntityEx")
public class ExampleEntityExDo extends ExampleEntityDo {
@Override
@AttributeName("nameEx")
public DoValue<String> name() { (1)
return doValue("nameEx");
}| 1 | Rename name attribute of superclass to nameEx |
16.7. Interfaces to Data Objects
Use the basic data object interface IDoEntity to model a data object hierarchy with own base interfaces and a set of implementing classes.
Interfaces extending IDataObject do not need a @TypeName annotation, since they are never directly serialized or deserialized.
The interfaces may be used as types for attributes within a data object. At runtime the concrete classes implementing the interfaces are serialized and their @TypeName annotation value is used.
16.8. Equals and Hashcode
The Data Object base class DoEntity defines a generic equals() and hashCode() implementation considering all attributes of a data object for equality.
A data object is equals to another data object, if the Java class of both data objects is identical and the attribute maps (including their nested values) of both data objects are equals.
For futher details see:
-
org.eclipse.scout.rt.platform.dataobject.DoEntity.equals(Object) -
org.eclipse.scout.rt.platform.dataobject.DoNode.equals(Object)
16.9. Generic DoEntity
An instance of the DoEntity class can represent any kind of JSON document.
If the JSON document contains no type attributes or no matching data object class exists at runtime, the JSON document is deserialized into a raw DoEntity instance holding all attributes.
To access the attributes of the data object a set of generic getter methods may be used by specifying the attribute name.
A generic JSON document is deserialized into a generic tree-like structure of nested DoEntity instances.
If the serialized JSON document contains a _type and/or _typeVersion attribute, the attribute and its value is added as attribute to the generic raw DoEntity instance.
ExampleEntityDo entity = BEANS.get(ExampleEntityDo.class)
.withName("Example")
.withValues(1, 2, 3, 4, 5);
// access name attribute by its attribute name
Object name1 = entity.get("name"); (1)
String name2 = entity.get("name", String.class); (2)
String name3 = entity.getString("name"); (3)
// access values attribute by its attribute name
List<Object> values1 = entity.getList("values"); (4)
List<String> values2 = entity.getList("values", String.class); (5)
List<String> values3 = entity.getStringList("values"); (6)| 1 | Accessing value attribute, default type is Object |
| 2 | Accessing value attribute, specify the type as class object if known |
| 3 | Accessing value attribute, convenience method for a set of common types |
| 4 | Accessing list attribute, default type is Object |
| 5 | Accessing list attribute, specify the type as class object if known |
| 6 | Accessing list attribute, convenience method for a set of common types |
Apart of the convenience methods available directly within the DoEntity class, the DataObjectHelper class contains a set of further convenience methods to access raw values of a data object.
16.9.1. Accessing number values
If a generic JSON document is deserialized to a DoEntity class without using a subclass specifying the attribute types, all attributes of type JSON number are deserialized into the smallest possible Java type.
For instance the number value 42 is deserialized into an Integer value, a large number may be deserialized into a BigInteger or BigDecimal if it is a floating point value.
Using the convenience method DoEntity.getDecimal(…) each number attribute is converted automatically into a BigDecimal instance on access.
If a generic JSON document is deserialized, only a set of basic Java types like String, Number, Double are supported. Every JSON object is deserialized into a (nested) DoEntity structure, which internally is represented by a nested structure of Map<String, Object>.
|
16.10. Map of objects
To build map-like a data object (corresponds to Map<String, T>), the DoMapEntity<T> base class may be used.
@TypeName("ExampleMapEntity")
public class ExampleMapEntityDo extends DoMapEntity<ExampleEntityDo> {
}The example JSON document of ExampleMapEntityDo instance with two elements:
{
"_type" : "ExampleMapEntity",
"mapAttribute1" : {
"_type" : "ExampleEntity",
"name" : "example-1",
"values" : [1,2,3,4,5]
},
"mapAttribute2" : {
"_type" : "ExampleEntity",
"name" : "example-2",
"values" : [6,7,8,9]
}
} ExampleMapEntityDo mapEntity = BEANS.get(ExampleMapEntityDo.class);
mapEntity.put("mapAttribute1",
BEANS.get(ExampleEntityDo.class)
.withName("Example")
.withValues(1, 2, 3, 4, 5));
mapEntity.put("mapAttribute2",
BEANS.get(ExampleEntityDo.class)
.withName("Example")
.withValues(6, 7, 8, 9));
ExampleEntityDo attr1 = mapEntity.get("mapAttribute1"); (1)
Map<String, ExampleEntityDo> allAttributes = mapEntity.all(); (2)| 1 | Accessing attribute using get method returns the attribute of declared type T |
| 2 | Accessing all attributes using all method returns a map with all attributes of type T |
A DoMapEntity<T> subclass may declare custom attributes of another type than T (e.g. an integer size attribute). If attributes of other types are used, using the all method results in a ClassCastException since not all attributes are of the same type any longer.
|
16.11. IDataObject Interface - Data Objects with unknown structure
According to the JSON specification a JSON document at top level may contain a object or an array. If a JSON string of unknown structure is deserialized, the common super interface IDataObject may be used as target type for the call to the deserializer:
String json = "<any JSON content>";
IDataObjectMapper mapper = BEANS.get(IDataObjectMapper.class);
IDataObject dataObject = mapper.readValue(json, IDataObject.class);
if (dataObject instanceof DoEntity) {
// handle object content
}
else if (dataObject instanceof DoList) {
// handle array content
}16.12. Ad-Hoc Data Objects
The DoEntityBuilder may be used to build ad-hoc data objects without a concrete Java class defining its attributes.
DoEntity entity = BEANS.get(DoEntityBuilder.class)
.put("attr1", "foo")
.put("attr2", "bar")
.putList("listAttr", 1, 2, 3)
.build(); (1)
String entityString = BEANS.get(DoEntityBuilder.class)
.put("attr1", "foo")
.put("attr2", "bar")
.putList("listAttr", 1, 2, 3)
.buildString(); (2)| 1 | Builder for a DoEntity object |
| 2 | Builder for the string representation of a DoEntity objects |
16.13. Maven Dependencies
The Scout data object implementation does not reference any specific Java serialization library or framework.
The basic building blocs of data objects are part of the Scout platform and to not reference any thirdparty libraries.
At runtime an implementation of the IDataObjectMapper interface must be provided.
The Scout default implementation based on the JSON library Jackson is provided by adding a maven dependency to the module org.eclipse.scout.rt.jackson.
The dependency to this module must be added in the top-level .dev/.app module.
A dependency within the program code is not necessaray as long as no specific Jackson features should be used within the application code.
16.14. Data Object Inventory
The class org.eclipse.scout.rt.platform.dataobject.DataObjectInventory provides access to all available data objects at runtime.
For each data object all available attributes and their properties (name, type, accessor method and format pattern) are available:
Map<String, DataObjectAttributeDescriptor> attributes =
BEANS.get(DataObjectInventory.class).getAttributesDescription(ExampleEntityDo.class);
attributes.forEach(
(key, value) -> System.out.println("Attribute " + key + " type " + value.getType()));Apart from attribute descriptions, the inventory provides access to type name and type version of each data object class.
16.15. Extending with custom serializer and deserializer
The application scoped beans DataObjectSerializers resp. DataObjectDeserializers define the available serializer and deserializer classes used to marshal the data objects.
Own custom serializer and deserializer implementations can be added by replacing the corresponding base class and register its own custom serializer or deserializer.
16.16. Enumerations within Data Objects
Implementations of org.eclipse.scout.rt.dataobject.enumeration.IEnum add a stringValue() method to each enumeration value, guaranteeing a constant, fixed string value for each enumeration value.
An arbitrary Java enum may be used within a data object, but does not guarantee a stable serialized value, if an enumeration value is changed in future.
Additionally implementations of IEnum can be annotated with @EnumName and @EnumVersion to support handling of different versions and migration between.
All instances of IEnum may be used within data objects and are automatically serialized to their JSON string value representation and deserialized back to the correct Java class instance.
The default resolver mechanism for IEnum (see org.eclipse.scout.rt.dataobject.enumeration.EnumResolver) matches the given string with the available string values in the current enumeration implementation to look up the matching enumeration value.
An optional static resolve() method handles the resolve of a given string value into the correct enumeration value allowing to support even string values, whose enumeration values where changed or deleted.
@EnumName("scout.FixtureEnum")
@EnumVersion("scout-8.0.0.036")
public enum ExampleEnum implements IEnum {
ONE("one"),
TWO("two"),
THREE("three");
private final String m_stringValue;
private ExampleEnum(String stringValue) {
m_stringValue = stringValue;
}
@Override
public String stringValue() {
return m_stringValue;
}
public static final ExampleEnum resolve(String value) { (1)
// custom null handling
if (value == null) {
return null;
}
switch (value) {
// custom handling of old values (assuming 'old' was used in earlier revisions)
case "one":
return ONE;
case "two":
return TWO;
case "three":
return THREE;
case "four":
return THREE;
default:
// custom handling of unknown values
throw new AssertionException("unsupported status value '{}'", value);
}
}
}| 1 | Optional resolve method |
16.17. Typed IDs within Data Objects
Implementations of org.eclipse.scout.rt.dataobject.id.IId<WRAPPED_TYPE> interface wrap an arbitrary value adding a concrete Java type to a scalar value.
E.g. the key of an example entity which technically is a UUID becomes an instance of the ExampleId class.
All instances of IId may be used within data objects and are automatically serialized to their JSON string representation of the wrapped value and deserialized back to the correct Java class instance.
An exampleId instance may then be used as type-safe parameter for further referencing a given example entity record, for instance as attribute value within a data object.
@IdTypeName("scout.ExampleId")
public static final class ExampleId extends AbstractUuId {
private static final long serialVersionUID = 1L;
public static ExampleId create() {
return new ExampleId(UUID.randomUUID());
}
public static ExampleId of(UUID id) {
if (id == null) {
return null;
}
return new ExampleId(id);
}
public static ExampleId of(String id) {
if (id == null) {
return null;
}
return new ExampleId(UUID.fromString(id));
}
private ExampleId(UUID id) {
super(id);
}
}17. REST
17.1. REST Resource Conventions
| HTTP Method | CRUD | Description |
|---|---|---|
POST |
Create |
Is most-often used to create new resources. POST is not idempotent. Making two identical POST requests will most-likely result in two resources containing the same information or the action executed twice. |
GET |
Read |
Only used to read or retrieve a representation of a resource. According to the HTTP specification GET (and HEAD) requests are used to read data and must not change anything! If a REST API wants to violate the specification, such requests must be protected against CSRF which is not enabled for GET and HEAD requests by default. See the Scout Bean GET requests are idempotent, which means that making multiple identical requests ends up having the same result as a single request (assuming the data has not been changed in the meantime). |
PUT |
Update/Replace |
Is most-often used to update resources. PUT expects to send the complete resource (not like PATCH) and is idempotent. In other words, if you create or update a resource using PUT and then make that same call again, the resource is still there and still has the same state as it did with the first call. If, for instance, calling PUT on a resource increments a counter within the resource, the call is no longer idempotent. In such a scenario it is strongly recommended to use POST for non-idempotent requests. |
PATCH |
Update |
PATCH is used to update resources. The PATCH request typically only contains the changes to the resource, not the complete resource. PATCH is not required to be idempotent. But it is possible to implement it in a way to be idempotent, which also helps prevent bad outcomes from collisions between multiple requests on the same resource. |
DELETE |
Delete |
Used to delete a resource. DELETE operations are idempotent concerning the result but may return another status code after the first deletion (e.g. 404 NOT FOUND). |
17.2. REST Resource Provider
A REST resource using the JAX-RS API is implemented by a POJO class annotated with a set of annotations.
The Scout module org.eclipse.scout.rt.rest contains the basic IRestResource marker interface which integrates REST resources within the Scout framework.
The interface is annotated by @Bean allowing the Scout platform to load and register all REST resources automatically at startup using the Jandex class inventory.
@Path("example")
public class ExampleResource implements IRestResource {
@GET
@Path("{id}")
@Produces(MediaType.APPLICATION_JSON)
public ExampleEntityDo getExamlpeEntity(@PathParam("id") String id) {
return BEANS.get(ExampleEntityDo.class)
.withName("example-" + id)
.withValues(1);
}
}17.2.1. REST Resource Registration
All available REST resources are automatically registered by the RestApplication class while the Scout platform startup.
Add the following snippet to your web.xml file to expose your REST API using the /api context path:
<!-- JAX-RS Jersey Servlet -->
<servlet>
<servlet-name>api</servlet-name>
<servlet-class>org.glassfish.jersey.servlet.ServletContainer</servlet-class>
<init-param>
<param-name>javax.ws.rs.Application</param-name>
<param-value>org.eclipse.scout.rt.rest.RestApplication</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>api</servlet-name>
<url-pattern>/api/*</url-pattern>
</servlet-mapping>17.2.2. Extend REST Application
The JAX-RS application API (javax.ws.rs.core.Application) allows a REST application implementation to specify a set of classes, a set of singleton instances and a map of custom properties to be registered.
The Scout implementation of the REST application class org.eclipse.scout.rt.rest.RestApplication allows to contribute classes, singletons and properties without needing to extend the RestApplication class.
Three different contributor interfaces are available for contributions:
-
IRestApplicationClassesContributorto contribute any classes -
IRestApplicationSingletonsContributorto contribute any object instances (singletons) -
IRestApplicationPropertiesContributorto contribute key/value properties
public static class ExampleClassContributor implements IRestApplicationClassesContributor {
@Override
public Set<Class<?>> contribute() {
return Collections.singleton(MyCustomExample.class);
}
}17.2.3. Data Objects
Scout data objects may be used as request and response objects for REST APIs. See Chapter 16 for details and examples.
17.2.4. Marshaller
A REST API may be used by non-Java consumers. In order to communicate using a platform-independent format, usually REST services use JSON as transport format.
The marshaller between Java data objects and JSON is abstracted in the JAX-RS specification.
Using the @Produces(MediaType.APPLICATION_JSON) annotation, each REST service method specifies the produces data format.
The Scout REST integration uses the popular Jackson library as default marshaller.
17.2.5. RunContext
Like a usual service call using the Scout service tunnel a REST request must ensure that processing of the request takes place within a RunContext.
The HttpServerRunContextFilter or HttpRunContextFilter can be used to intercept incoming REST requests and wrap them within a Scout RunContext.
HttpServerRunContextFilter can be used if a Scout server dependency is available. Optionally this filter also supports the creation of a Scout server session if this should be required (stateful). Refer to the javadoc for more details.
The HttpRunContextFilter on the other hand does not provide session support and is always stateless.
Therefore a REST resource implementation is not required to deal with setting up a RunContext to wrap the request within each method.
The filter must be added in the web.xml configuration file and should be configured to be called after the authentication filter.
The filter expects that the authentication has been performed and that a subject is available (JAAS context).
All following filters and servlets and thus also the REST resources run automatically in the correct context.
<filter>
<filter-name>HttpServerRunContextFilter</filter-name>
<filter-class>org.eclipse.scout.rt.server.context.HttpServerRunContextFilter</filter-class>
<init-param>
<param-name>session</param-name>
<param-value>false</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>HttpServerRunContextFilter</filter-name>
<url-pattern>/api/*</url-pattern>
</filter-mapping>Beside the subject and other attributes the HttpServerRunContextFilter and HttpRunContextFilter setup the Correlation ID, as well as the locale.
Both values are read from the incoming request header, the caller must ensure that the headers Accept-Language and X-Scout-Correlation-Id are set accordingly.
17.3. Dependency Management
Scout REST services based on JAX-RS using the Jersey library and the Jackson JSON marshaller need a maven dependency to jersey-media-json-jackson in your application pom.xml.
This enables to use Jackson as JAX-RS marshaller with the Jersey JAX-RS implementation.
Additionally a dependency to the Scout module org.eclipse.scout.rt.rest.jackson is necessary.
This module adds a set of Jackson additions in order to use the Jackson library together with Scout data objects.
<!-- JAX-RS Jersey -->
<dependency>
<groupId>org.glassfish.jersey.containers</groupId>
<artifactId>jersey-container-servlet-core</artifactId>
</dependency>
<dependency>
<groupId>org.glassfish.jersey.inject</groupId>
<artifactId>jersey-hk2</artifactId>
</dependency>
<dependency>
<groupId>org.glassfish.jersey.media</groupId>
<artifactId>jersey-media-json-jackson</artifactId>
</dependency>
<!-- Jackson/Scout integration -->
<dependency>
<groupId>org.eclipse.scout.rt</groupId>
<artifactId>org.eclipse.scout.rt.rest.jackson</artifactId>
</dependency>17.4. REST Client
The Scout module org.eclipse.scout.rt.rest offers a set of helper classes in order to call REST services.
Each REST service endpoint is represented by a specific REST resource client helper class. The (usually application scoped bean) class is used to specify the resource URL and additional properties used to build up the connection (authentication, additional headers,…). Further it provides a call-back method for transforming unsuccessful responses into appropriate exception.
At least the REST resource’s base URI must be specified:
public class ExampleRestClientHelper extends AbstractRestClientHelper {
@Override
protected String getBaseUri() {
return "https://api.example.org/"; (1)
}
@Override
protected RuntimeException transformException(RuntimeException e, Response response) { (2)
if (response != null && response.hasEntity()) {
ErrorDo error = response.readEntity(ErrorResponse.class).getError();
throw new VetoException(error.getMessage())
.withTitle(error.getTitle());
}
return e;
}
}| 1 | Declare base uri. |
| 2 | Custom exception transformer that is used as default strategy for all invocations prepared by this helper. (This is just for demonstration. Better extend
org.eclipse.scout.rt.rest.client.proxy.AbstractEntityRestClientExceptionTransformer). |
Based on the helper class, an example REST resource client may be implemented:
public class ExampleResourceClient implements IRestResourceClient {
protected static final String RESOURCE_PATH = "example";
protected ExampleRestClientHelper helper() {
return BEANS.get(ExampleRestClientHelper.class);
}
public ExampleEntityDo getExampleEntity(String id) {
WebTarget target = helper().target(RESOURCE_PATH)
.path("/{id}")
.resolveTemplate("id", id);
return target.request()
.accept(MediaType.APPLICATION_JSON)
.get(ExampleEntityDo.class); (1)
}
public ExampleEntityDo updateExampleEntity(String id, ExampleEntityDo entity) {
WebTarget target = helper().target(RESOURCE_PATH)
.path("/{id}")
.resolveTemplate("id", id);
return target.request()
.accept(MediaType.APPLICATION_JSON)
.post(Entity.json(entity), ExampleEntityDo.class); (2)
}
public void deleteExampleEntity(String id) {
WebTarget target = helper().target(RESOURCE_PATH)
.path("/{id}")
.resolveTemplate("id", id);
Response response = target.request().delete(); (3)
response.close();
}
public ExampleEntityDo getExampleEntityCustomExceptionHandling(String id) {
WebTarget target = helper().target(RESOURCE_PATH, this::transformCustomException) (4)
.path("/{id}")
.resolveTemplate("id", id);
return target.request()
.accept(MediaType.APPLICATION_JSON)
.get(ExampleEntityDo.class);
}
protected RuntimeException transformCustomException(RuntimeException e, Response r) {
if (r != null && r.hasEntity() && MediaType.TEXT_PLAIN_TYPE.equals(r.getMediaType())) {
String message = r.readEntity(String.class);
throw new VetoException(message);
}
return e;
}
}| 1 | HTTP GET example: Directly read response into an object. Exceptions are transformed transparently and the underlying resources are released (e.g. HTTP client). |
| 2 | HTTP POST example: Again, directly read the response into an object. |
| 3 | HTTP DELETE example: This delete operation does not send a response if it was successful. Hence close the returned Response explicitly to release underlying resources
(see next line). Note: Unsuccessful responses are already handled by the REST client proxy. |
| 4 | Use custom exception transformer. |
17.5. REST Cancellation Support
REST and the underlying HTTP protocol do not provide an explicit way to cancel running requests. Typically, a client terminates its connection to the HTTP server if it is no longer interested in the response. REST resources would have to monitor TCP connections and interpret a close as cancellation. Depending on the abstraction of the REST framework, connection events are not passed through and the cancellation is only recognized when the response is written to the closed connection. Until this happens, however, backend resources are used unnecessarily.
Scout’s standard REST integration implements the described approach by closing the connection without any further action. It is not possible to react to this on the resource side.
In order to enable a real cancellation, Scout also provides all necessary elements to assign an ID to a request, to manage these IDs in the backend during execution and to cancel transactions in the event of a cancellation. The following steps must be taken for their use:
17.5.1. Cancellation Resource and Resource Client
Scout does not impose nor provide a cancellation resource. It must be implemented by the project:
@Path("cancellation")
public class CancellationResource implements IRestResource {
@PUT
@Path("{requestId}")
public void cancel(@PathParam("requestId") String requestId) {
String userId = BEANS.get(IAccessControlService.class).getUserIdOfCurrentSubject(); (1)
BEANS.get(RestRequestCancellationRegistry.class).cancel(requestId, userId); (2)
}
}| 1 | Resolve the userId of the current user. This is optional and may depend on the current project. |
| 2 | Invoke the cancellation registry for the given requestId and userId. |
public class CancellationResourceClient implements IRestResourceClient {
protected static final String RESOURCE_PATH = "cancellation";
protected CancellationRestClientHelper helper() {
return BEANS.get(CancellationRestClientHelper.class);
}
public void cancel(String requestId) {
WebTarget target = helper().target(RESOURCE_PATH)
.path("{requestId}")
.resolveTemplate("requestId", requestId);
Response response = target.request()
.put(Entity.json(""));
response.close();
}
}17.5.2. Install Cancellation Request Filter
To assign an ID to each request, an appropriate client request filter must be registered:
public class CancellationRestClientHelper extends AbstractRestClientHelper {
@Override
protected String getBaseUri() {
return "https://api.example.org/";
}
@Override
protected void registerRequestFilters(ClientBuilder clientBuilder) {
super.registerRequestFilters(clientBuilder);
clientBuilder.register(new RestRequestCancellationClientRequestFilter(this::cancelRequest)); (1)
}
protected void cancelRequest(String requestId) {
BEANS.get(CancellationResourceClient.class).cancel(requestId); (2)
}
}| 1 | Register the RestRequestCancellationClientRequestFilter that assigns a UUID to every request, which is sent as an HTTP header named X-ScoutRequestId. |
| 2 | Binds the actual cancel-operation to the cancel Method (in this case the cancellation rest resource client from above). |
17.5.3. Implement Cancellation Servlet Filter
Requests arriving at the backend need to be registered in the cancellation registry. This is done by a servlet filter (Note: REST
container filters would have two issues: 1. there is no real interceptor around the resource call, but only a ContainerRequestFilter that is
invoked before and a ContainerResponseFilter which is invoked after the the request is passed to the resource. 2. Cancellation in
Scout is tied to an ITransaction that are managed by a RunContext and observed and controlled by a RunMonitor. Depending on
sub-RunContexts and their transaction isolation it might happen, that the transaction visible in a container filter is not controlled by the
currently active RunMonitor. Therefore, a cancel request would not cancel the transaction.)
public class RestRequestCancellationServletFilter extends AbstractRestRequestCancellationServletFilter {
@Override
protected Object resolveUserId(HttpServletRequest request) {
return BEANS.get(IAccessControlService.class).getUserIdOfCurrentSubject(); (1)
}
}| 1 | Implement the same userId Lookup as in the CancellationResource. |
And finally, declare the servlet filter in your web.xml:
<filter>
<filter-name>RestRequestCancellationFilter</filter-name>
<filter-class>org.eclipse.scout.docs.snippets.rest.RestRequestCancellationServletFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>RestRequestCancellationFilter</filter-name>
<url-pattern>/api/*</url-pattern>
</filter-mapping>| Make sure the cancellation filter is registered after the HttpServerRunContextFilter. |
18. Webservices with JAX-WS
The Java API for XML-Based Web Services (JAX-WS) is a Java programming language API for creating web services. JAX-WS is one of the Java XML programming APIs, and is part of the Java EE platform.
Scout facilitates working with webservices, supports you in the generation of artifacts, and provides the following functionality:
18.1. Functionality
-
ready to go Maven profile for easy webservice stub and artifact generation
-
full JAX-WS 2.2 compliance
-
JAX-WS implementor independence
-
provides an up front port type EntryPoint to enforce for authentication, and to run web requests in a RunContext
-
adds cancellation support for on-going webservice requests
-
provides a port cache for webservice consumers
-
allows to participate in 2PC protocol for webservice consumers
-
allows to provide 'init parameters' to handlers
18.2. JAX-WS implementor and deployment
18.2.1. JAX-WS version and implementor
The JAX-WS Scout integration provides a thin layer on top of JAX-WS implementors to facilitate working with webservices. It depends on the JAX-WS 2.2.x API as specified in JSR 224. It is implementor neutral, and was tested with with the following implementations:
-
JAX-WS RI (reference implementation) as shipped with Java 7 and Java 8. Please note that starting with Java 11 this is no longer part of the JRE.
-
JAX-WS METRO (2.2.10)
-
Apache CXF (3.1.3)
The integration does not require you to bundle the JAX-WS implementor with your application, which is a prerequisite for running in an EE container.
18.2.2. Running JAX-WS in a servlet container
A servlet container like Apache Tomcat typically does not ship with a JAX-WS implementor. As the actual implementor, you can either use JAX-WS RI as shipped with the JRE, or provide a separate implementor like JAX-WS METRO or Apache CXF in the form of a Maven dependency. However, JAX-WS RI does not provide a servlet based entry point, because the Servlet API is not part of the Java SE specification.
When publishing webservices, it therefore is easiest to ship with a separate implementor: Declare a respective Maven dependency in your webbapp project - that is the Maven module typically containing the application’s web.xml.
18.2.3. Running JAX-WS in a EE container
When running in an EE container, the container typically ships with a JAX-WS implementor. It is highly recommended to use that implementor, primarily to avoid classloading issues, and to further profit from the container’s monitoring and authentication facility. Refer to the containers documentation for more information.
18.2.4. Configure JAX-WS implementor
JAX-WS Scout integration is prepared to run with different implementors. Unfortunately, some implementors do not implement the JSR exactly, or some important functionality is missing in the JSR. To address this fact without loosing implementor independence, the delegate bean JaxWsImplementorSpecifics exists.
As of now, Scout ships with three such implementor specific classes, which are activated via config.properties by setting the property scout.jaxws.implementor with its fully qualified class name. By default, JAX-WS METRO implementor is installed.
For instance, support for Apache CXF implementor is activated as following:
scout.jaxws.implementor=org.eclipse.scout.rt.server.jaxws.implementor.JaxWsCxfSpecifics| class | description |
|---|---|
JaxWsRISpecifics |
implementor specifics for JAX-WS Reference Implementation (RI) as contained in JRE |
JaxWsMetroSpecifics |
implementor specifics for JAX-WS METRO implementation |
JaxWsCxfSpecifics |
implementor specifics for Apache JAX-WS CXF implementation |
Of course, other implementors can be used as well. For that to work, install your own JaxWsImplementorSpecifics class, and reference its fully qualified name in config.properties.
JaxWsImplementorSpecifics
This class encapsulates functionality that is defined in JAX-WS JSR 224, but may diverge among JAX-WS implementors. As of now, the following points are addressed:
-
missing support in JSR to set socket connect and read timeout;
-
proprietary 'property' to set response code in Apache CXF;
-
when working with Apache CXF, response header must be set directly onto Servlet Response, and not via
MessageContext; -
when working with JAX-WS METRO or JAX-WS RI, the handler’s return value is ignored in one-way communication; instead, the chain must be exited by throwing a webservice exception;
Learn more about how to configure a JAX-WS implementor: Section 18.2.4
Configure JAX-WS Maven dependency in pom.xml
The effective dependency to the JAX-WS implementor is to be specified in the pom.xml of the webapp module (not the server module). That allows for running with a different implementor depending on the environment, e.g. to provide the implementor yourself when starting the application from within your IDE in Jetty, or to use the container’s implementor when deploying to an EE enabled application server. Even if providing the very same implementor for all environments yourself, it is good practice to do the configuration in the webapp module.
A generally applicable configuration cannot be given, because the effective configuration depends on the implementor you choose, and whether it is already shipped with the application server you use. However, if JAX-WS RI is sufficient, you do not have to specify an implementor at all because already contained in JRE.
If running in an EE application server, refer to the containers documentation for more information.
Listing 110 provides sample configuration for shipping with JAX_WS METRO and Listing 111 does the same for Apache CXF
<!-- JAX-WS METRO not bundled with JRE -->
<dependency>
<groupId>com.sun.xml.ws</groupId>
<artifactId>jaxws-rt</artifactId>
<version>...</version>
</dependency><!-- JAX-WS Apache CXF -->
<dependency>
<groupId>org.apache.cxf</groupId>
<artifactId>cxf-rt-frontend-jaxws</artifactId>
<version>...</version>
</dependency>
<dependency>
<groupId>org.apache.cxf</groupId>
<artifactId>cxf-rt-transports-http</artifactId>
<version>...</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>...</version>
</dependency>Configure JAX-WS servlet in web.xml
This section describes the configuration of the entry point Servlet to publish webservices. If working with webservice consumers only, no configuration is required.
Similar to the pom.xml as described in Section 18.2.4.2, the web.xml differs from implementor to implementor, and whether the implementor is already shipped with the application server. Nevertheless, the following Listing 112 show a sample configuration for JAX-WS METRO and Listing 113 for Apache CXF.
<!-- JAX-WS METRO not bundled with JRE -->
<context-param>
<param-name>com.sun.xml.ws.server.http.publishStatusPage</param-name>
<param-value>true</param-value>
</context-param>
<context-param>
<param-name>com.sun.xml.ws.server.http.publishWSDL</param-name>
<param-value>true</param-value>
</context-param>
<listener>
<listener-class>com.sun.xml.ws.transport.http.servlet.WSServletContextListener</listener-class>
</listener>
<servlet>
<servlet-name>jaxws</servlet-name>
<servlet-class>com.sun.xml.ws.transport.http.servlet.WSServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>jaxws</servlet-name>
<url-pattern>/jaxws/*</url-pattern> (1)
</servlet-mapping>| 1 | the base URL where to publish the webservice endpoints |
<!-- JAX-WS Apache CXF -->
<servlet>
<display-name>CXF Servlet</display-name>
<servlet-name>jaxws</servlet-name>
<servlet-class>org.apache.cxf.transport.servlet.CXFServlet</servlet-class>
<init-param>
<param-name>config-location</param-name>
<param-value>/WEB-INF/cxf-jaxws.xml</param-value> (1)
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>jaxws</servlet-name>
<url-pattern>/jaxws/*</url-pattern> (2)
</servlet-mapping>| 1 | Apache CXF specific configuration file for endpoints to be published. See Section 18.5.8.2 for more information. |
| 2 | the base URL where to publish the webservice endpoints |
But, if running in an EE container, it is most likely that a Servlet configuration must not be configured, because the endpoints are discovered by the application server, or registered in a vendor specific way. Refer to the containers documentation for more information.
| Some application servers like Oracle WebLogic Server (WLS) allow the port types to be registered as a Servlet in web.xml. However, this is vendor specific, and works despite the fact that port type does not implement 'javax.servlet.Servlet'. |
| Do not forget to exclude the webservice’s Servlet URL pattern from authentication filter. |
18.3. Modularization
Scout JAX-WS integration does not prescribe how to organize your webservices in terms of Maven modules. You could either put all your webservices directly into the server module, or create a separate jaxws module containing all webservices, or even create a separate jaxws module for each webservice. Most often, the second approach of a single, separate jaxws module, which the server module depends on, is chosen.
This is mainly because of the following benefits:
-
annotation processing must not be enabled for the entire server module
-
one module to build all webservice artifacts at once
-
easier to work with shared element types among webservices
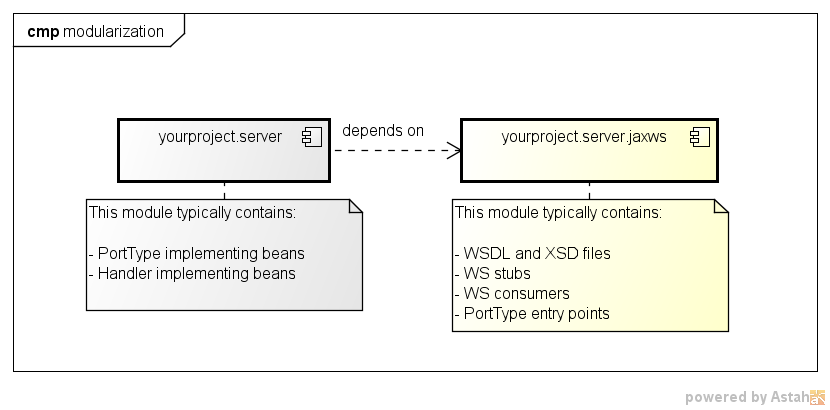
It is important to note, that the server depends on the jaxws module, and not vice versa. The jaxws module is primarily of technical nature, meaning that it knows how to generate its WS artifacts, and also contains those. However, implementing port type beans and even implementing handler beans are typically put into the server module to the access service and database layer. On the other hand, WS clients may be put into jaxws module, because they rarely contain any project specific business logic.
You may ask yourself, how the jaxws module can access the implementing port type and handlers located in the server module. That works because of the indirection via bean manager, and because there is a flat classpath at runtime.
See WebServiceEntryPoint for more information.
18.4. Build webservice stubs and artifacts
18.4.1. Configure webservice stub generation via wsimport
The Maven plugin 'com.helger.maven:jaxws-maven-plugin' with the goal 'wsimport' is used to generate a webservice stub from a WSDL file and its referenced XSD schema files. If your Maven module inherits from the Scout module 'maven_rt_plugin_config-master', the 'jaxws' profile is available, which activates automatically upon the presence of a 'WEB-INF/wsdl' folder. Instead of inheriting from that module, you can alternatively copy the 'jaxws' profile into your projects parent POM module.
This profile is for convenience purpose, and provides a ready-to-go configuration to generate webservice stubs and webservice provider artifacts. It configures the 'jaxws-maven-plugin' to look for WSDL and XSD files in the folder 'src/main/resources/WEB-INF/wsdl', and for binding files in the folder '/src/main/resources/WEB-INF/binding'. Upon generation, the stub will be put into the folder 'target/generated-sources/wsimport'.
The profiles requires the Scout runtime version to be specified, and which is used to refer to org.eclipse.scout.jaxws.apt module to generate webservice provider artifacts. However, this version is typically defined in pom.xml of the parent module, because also used to refer to other Scout runtime artifacts.
<properties>
<org.eclipse.scout.rt.version>5.2.0-SNAPSHOT</org.eclipse.scout.rt.version>
</properties>If your project design envisions a separate JAR module per WSDL, you simply have to set the property 'jaxws.wsdl.file' with the name of your WSDL file in the module’s pom.xml (example in Listing 115).
<properties>
<jaxws.wsdl.file>YourWebService.wsdl</jaxws.wsdl.file> (1)
</properties>| 1 | name of the wsdl file |
Otherwise, if having multiple WSDL files in your JAR module, some little more configuration is required, namely a respective execution section per WSDL file.
Thereby, the 'id' of the execution section must be unique.
Scout 'jaxws' profile already provides one such section, which is used to generate the stub for a single WSDL file (see such configuration in Listing 115), and names it 'wsimport-1'.
It is simplest to name the subsequent execution sections 'wsimport-2', 'wsimport-3', and so on.
For each execution section, you must configure its unique id, the goal 'wsimport', and in the configuration section the respective wsdlLocation and wsdlFile.
For 'wsimport' to work, wsdlLocation is not required.
However, that location will be referenced in generated artifacts to set the wsdl location via @WebService and @WebServiceClient.
The complete configuration is presented in Listing 116.
If you decide to configure multiple WSDL files in your POM as described in Listing 116, the configuration defined in the parent POM (maven_rt_plugin_config-master) and expecting a configuration as presented in Listing 115 needs to be overridden, therefore one of your execution id needs to be wsimport-1.
|
<build>
<plugins>
<plugin>
<groupId>com.helger.maven</groupId>
<artifactId>jaxws-maven-plugin</artifactId>
<executions>
<!-- YourFirstWebService.wsdl -->
<execution> (1)
<!-- DO NOT CHANGE THE ID: 'wsimport-1';
it overrides an execution defined in the parent pom -->
<id>wsimport-1</id> (2)
<goals>
<goal>wsimport</goal> (3)
</goals>
<configuration>
<wsdlLocation>WEB-INF/wsdl/YourFirstWebService.wsdl</wsdlLocation> (4)
<wsdlFiles>
<wsdlFile>YourFirstWebService.wsdl</wsdlFile> (5)
</wsdlFiles>
</configuration>
</execution>
<!-- YourSecondWebService.wsdl -->
<execution> (6)
<id>wsimport-2</id>
<goals>
<goal>wsimport</goal>
</goals>
<configuration>
<wsdlLocation>WEB-INF/wsdl/YourSecondWebService.wsdl</wsdlLocation>
<wsdlFiles>
<wsdlFile>YourSecondWebService.wsdl</wsdlFile>
</wsdlFiles>
</configuration>
</execution>
...
</executions>
</plugin>
</plugins>
</build>| 1 | declare an execution section for each WSDL file |
| 2 | give the section a unique id (wsimport-1, wsimport-2, wsimport-3, …) |
| 3 | specify the goal 'wsimport' to build the webservice stub |
| 4 | specify the project relative path to the WSDL file |
| 5 | specify the relative path to the WSDL file (relative to 'WEB-INF/wsdl') |
| 6 | declare an execution section for the next WSDL file |
Further, you can overwrite any configuration as defined by 'jaxws-maven-plugin'. See http://www.mojohaus.org/jaxws-maven-plugin/ for supported configuration properties.
Also, it is good practice to create a separate folder for each WSDL file, which also contains all its referenced XSD schemas. Then, do not forget to change the properties wsdlLocation and wsdlFile accordingly.
18.4.2. Customize WSDL components and XSD schema elements via binding files
By default, all XML files contained in folder 'WEB-INF/binding' are used as binding files. But, most often, you will have a global binding file, which applies to all your WSDL files, and some custom binding files different per WSDL file and XSD schema files. See how to explicitly configure binding files in Listing 117.
<!-- YourFirstWebService.wsdl -->
<execution>
...
<configuration>
...
<bindingFiles>
<bindingFile>global-bindings.xml</bindingFile> (1)
<bindingFile>your-first-webservice-ws-bindings.xml</bindingFile> (2)
<bindingFile>your-first-webservice-xs-bindings.xml</bindingFile> (3)
</bindingFiles>
</configuration>
</execution>
<!-- YourSecondWebService.wsdl -->
<execution>
...
<configuration>
...
<bindingFiles>
<bindingFile>global-bindings.xml</bindingFile> (1)
<bindingFile>your-second-webservice-ws-bindings.xml</bindingFile> (2)
<bindingFile>your-second-webservice-xs-bindings.xml</bindingFile> (3)
</bindingFiles>
</configuration>
</execution>| 1 | global binding file which applies to all XSD schema elements. See Listing 118 for an example. |
| 2 | custom binding file to customize the webservice’s WSDL components in the namespace http://java.sun.com/xml/ns/jaxws. See Listing 119 for an example. |
| 3 | custom binding file to customize the webservice’s XSD schema elements in the namespace http://java.sun.com/xml/ns/jaxb. See Listing 120 for an example. |
With binding files in place, you can customize almost every WSDL component and XSD element that can be mapped to Java, such as the service endpoint interface class, packages, method name, parameter name, exception class, etc.
The global binding file typically contains some customization for common data types like java.util.Date or java.util.Calendar, whereas the custom binding files are specific for a WSDL or XSD schema. See Section 18.7.
<bindings version="2.0"
xmlns="http://java.sun.com/xml/ns/jaxb"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xjc="http://java.sun.com/xml/ns/jaxb/xjc">
<globalBindings>
<xjc:javaType
name="java.util.Date"
xmlType="xsd:date"
adapter="org.eclipse.scout.rt.server.jaxws.adapter.UtcDateAdapter" />
<xjc:javaType
name="java.util.Date"
xmlType="xsd:time"
adapter="org.eclipse.scout.rt.server.jaxws.adapter.UtcTimeAdapter" />
<xjc:javaType
name="java.util.Date"
xmlType="xsd:dateTime"
adapter="org.eclipse.scout.rt.server.jaxws.adapter.UtcDateTimeAdapter" />
</globalBindings>
</bindings>By default, generated artifacts are put into the package corresponding to the element’s namespace. Sometimes, you like to control the package names, but you want to do that on a per-namespace basis, and not put all the artifacts of a webservice into the very same package. That is mainly to omit collisions, and to have artifacts shared among webservices not duplicated.
Two separate binding files are required to customize WSDL components and XSD schema elements.
That is because WSDL component customization is to be done in 'jaxws' namespace http://java.sun.com/xml/ns/jaxws, whereas XSD schema element customization in 'jaxb' namespace http://java.sun.com/xml/ns/jaxb.
<!-- binding to customize webservice components (xmlns=http://java.sun.com/xml/ns/jaxws) -->
<bindings xmlns="http://java.sun.com/xml/ns/jaxws"> (1)
<package name="org.eclipse.ws.yourfirstwebservice"/> (2)
</bindings>| 1 | customization via jaxws namespace: http://java.sun.com/xml/ns/jaxws |
| 2 | instructs to put all webservice components (port type, service) into package org.eclipse.ws.yourfirstwebservice |
<!-- binding to customize xsd schema elements (xmlns=http://java.sun.com/xml/ns/jaxb) -->
<bindings xmlns="http://java.sun.com/xml/ns/jaxb" version="2.1"> (1)
<!-- namespace http://eclipse.org/public/services/ws/soap -->
<bindings scd="x-schema::tns" xmlns:tns="http://eclipse.org/public/services/ws/soap">
<schemaBindings>
<package name="org.eclipse.ws.yourfirstwebservice" /> (2)
</schemaBindings>
</bindings>
<!-- namespace http://eclipse.org/public/services/ws/common/soap -->
<bindings scd="x-schema::tns" xmlns:tns="http://eclipse.org/public/services/ws/common/soap">
<schemaBindings>
<package name="org.eclipse.ws.common" /> (3)
</schemaBindings>
</bindings>
</bindings>| 1 | customization via jaxb namespace: http://java.sun.com/xml/ns/jaxb |
| 2 | instructs to put all XSD schema elements in namespace http://eclipse.org/public/services/ws/soap into package org.eclipse.ws.yourfirstwebservice |
| 3 | instructs to put all XSD schema elements in namespace http://eclipse.org/public/services/ws/common/soap into package org.eclipse.ws.common |
| wsimport allows to directly configure the package name for files to be generated (packageName). However, this is discouraged, because all artifacts are put into the very same package. Use package customization on a per-namespace basis instead. |
| For shared webservice artifacts, you can also use XJC binding compiler to generate those artifacts in advance, and then provide the resulting episode binding file (META-INF/sun-jaxb.episode) to wsimport. See http://www.mojohaus.org/jaxb2-maven-plugin/Documentation/v2.2/xjc-mojo.html for more information. |
18.4.3. Annotation Processing Tool (APT)
Annotation Processing (APT) is a tool which can be enabled to fire for annotated types during compilation. In JAX-WS Scout integration, it is used as a trigger to generate webservice port type implementations. Such an auto-generated port type implementation is called an entry point. It is to be published as the webservice’s endpoint, and acts as an interceptor for webservice requests. It optionally enforces for authentication, and makes the request to be executed in a RunContext. Then, it handles the web request to the effectively implementing port type bean for actual processing.
The entry point generated simplifies the actual port type implementation by removing lot of glue code to be written by hand otherwise. Of course, this entry point is just for convenience purpose, and it is up to you to make use of this artifact.
When using 'jaxws' Scout Maven profile, annotation processing is enabled for that module by default. But, an entry point for a webservice port type will only be generated if enabled for that port type, meaning that a class annotated with WebServiceEntryPoint pointing to that very endpoint interface is found in this module. Anyway, for a sole webservice consumer, it makes no sense to generate an entry point at all.
Enable Annotation Processing Tool (APT) in Eclipse IDE
In Eclipse IDE, the workspace build ignores annotation processing as configured in pom.xml. Instead, it must be enabled separately with the following files. Nevertheless, to simply run Maven build with annotation support from within Eclipse IDE, those files are not required.
| file | description |
|---|---|
Enables APT for this module via the property org.eclipse.jdt.core.compiler.processAnnotations=enabled |
|
Enables APT for this module via the property org.eclipse.jdt.apt.aptEnabled=true |
|
Specifies the annotation processor to be used (JaxWsAnnotationProcessor) and dependent artifacts |
18.4.4. Build webservice stubs and APT artifacts from console
Simply run mvn clean compile on the project. If you are experiencing some problems, run with -X debug flag to get a more detailed error message.
18.4.5. Build webservice stubs and APT artifacts from within Eclipse IDE
In the Eclipse IDE, there are three ways to generate webservice stubs and APT artifacts.
-
the implicit way on behalf of the workspace build and m2e integration (automatically, but sometimes not reliable)
-
the explicit but potentially slow way by doing a 'Update Maven Project' with 'clean projects' checked (Alt+F5)
-
the explicit and faster way by running a Maven build for that project. Thereto, right-click on the project or pom.xml, then select the menu 'Run As | Maven build…', then choose 'clean compile' as its goal and check 'Resolve workspace artifacts', and finally click 'Run'. Afterwards, do not forget to refresh the project by pressing F5.
If the webservice stub(s) or APT artifacts are not generated (anew or at all), delete the target folder manually, and continue according to procedure number three. A possible reason might be the presence of 'target\jaxws\wsartifact-hash'. Then, for each webservice, a 'hash file' is computed by 'wsimport', so that regeneration only occurs upon a change of WSDL or XSD files.
18.4.6. Exclude derived resources from version control
Stub and APT artifacts are derived resources, and should be excluded from version control. When working with Eclipse IDE, this is done automatically by eGit, because it adds derived resources to .gitignore (if configured to do so).
18.4.7. JaxWsAnnotationProcessor
JaxWsAnnotationProcessor is an annotation processor provided by Scout JAX-WS integration to generate an entry point for an endpoint interface during compilation. The instructions how to generate the entry point is given via a Java class or Java interface annotated with WebServiceEntryPoint annotation.
18.5. Provide a webservice
In this chapter, you will learn how to publish a webservice provider via an entry point.
18.5.1. The concept of an Entry Point
An entry point implements the endpoint interface (or port type interface), and is published as the webservice endpoint for that endpoint interface. The entry point itself is auto generated by JaxWsAnnotationProcessor during compile time, based on instructions as given by the respective class/interface annotated with WebServiceEntryPoint annotation. The entry point is responsible to enforce authentication and to run the web request in a RunContext. In turn, the request is propagated to the bean implementing the endpoint interface.
Figure 15 illustrates the endpoint’s class hierarchy and the message flow for a web request.
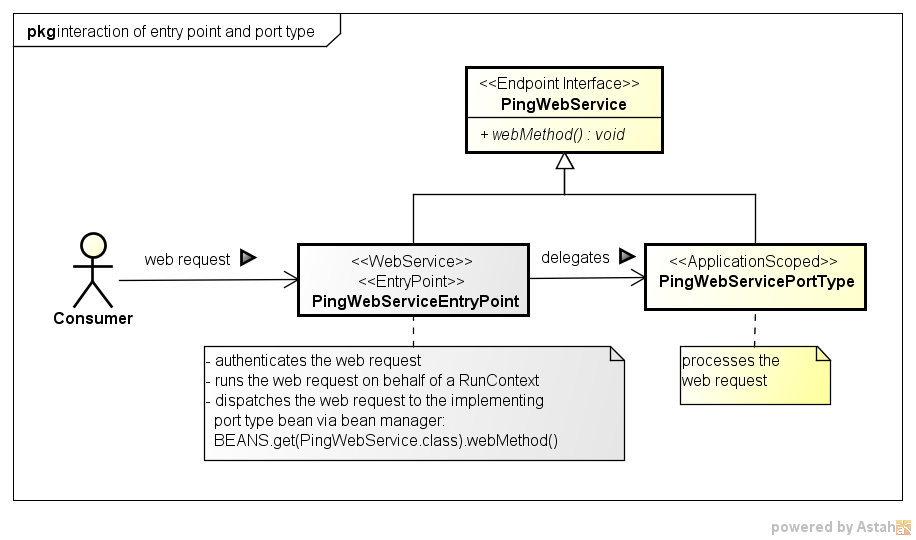
As you can see, both, entry point and port type implement the endpoint interface. But it is the entry point which is actually installed as the webservice endpoint, and which receives web requests. However, the webservice itself is implemented in the implementing bean, which typically is located in server module. See Section 18.3 for more information. Upon a web request, the entry point simply intercepts the web request, and then invokes the web method on the implementing bean for further processing.
See an example of an implementing port type bean, which is invoked by entry point.
Do not forget to annotate the implementing bean with ApplicationScoped annotation in order to be found by bean manager.
|
18.5.2. Generate an Entry Point as an endpoint interface
This section describes the steps required to generate an entry point. For demonstration purposes, a simple ping webservice is used, which provides a single method 'ping' to accept and return a String object.
See the WSDL file of ping webservice: Section 18.8.1
See the endpoint interface of ping webservice: Section 18.8.2
To generate an entry point for the webservice’s endpoint interface, create an interface as following in your jaxws project.
@WebServiceEntryPoint(endpointInterface = PingWebServicePortType.class) (2)
interface PingWebServiceEntryPointDefinition { (1)
}| 1 | Create an interface or class to act as an anchor for the WebServiceEntryPoint annotation. This class or interface has no special meaning, except that it declares the annotation to be interpreted by annotation processor. |
| 2 | Reference the endpoint interface for which an entry point should be generated for. Typically, the endpoint interface is generated by 'wsimport' and is annotated with WebService annotation. |
It is important to understand, that the interface PingWebServiceEntryPointDefinition solely acts as the anchor for the WebServiceEntryPoint annotation. This class or interface has no special meaning, except that it declares the annotation to be interpreted by annotation processor. Typically, this class is called Entry Point Definition.
If running mvn clean compile, an entry point is generated for that endpoint interface.
See the entry point as generated for ping webservice: Section 18.8.3
If you should experience some problems in the entry point generation, refer to Build webservice stubs and APT artifacts from within Eclipse IDE, or Build webservice stubs and APT artifacts from console.
18.5.3. Instrument the Entry Point generation
This section gives an overview on how to configure the entry point to be generated.
| attribute | description |
|---|---|
endpointInterface |
Specifies the endpoint interface for which to generate an entry point for. |
entryPointName |
Specifies the class name of the entry point generated. If not set, the name is like the name of the endpoint interface suffixed with EntryPoint. |
entryPointPackage |
Specifies the package name of the entry point generated. If not set, the package name is the same as of the element declaring this WebServiceEntryPoint annotation. |
serviceName |
Specifies the service name as declared in the WSDL file, and must be set if publishing the webservice via auto discovery in an EE container. Both, 'serviceName' and 'portName' uniquely identify a webservice endpoint to be published. |
portName |
Specifies the name of the port as declared in the WSDL file, and must be set if publishing the webservice via auto discovery in an EE container. Both, 'serviceName' and 'portName' uniquely identify a webservice endpoint to be published. |
wsdlLocation |
Specifies the location of the WSDL document. If not set, the location is derived from WebServiceClient annotation which is typically initialized with the 'wsdlLocation' as provided to 'wsimport'. |
authentication |
Specifies the authentication mechanism to be installed, and in which |
handlerChain |
Specifies the handlers to be installed. The order of the handlers is as declared. A handler is looked up as a bean, and must implement |
Besides the instructions which can be set via WebServiceEntryPoint annotation, it is further possible to contribute other annotations to the entry point. Simply declare the annotation of your choice as a sibling annotation to WebServiceEntryPoint annotation. In turn, this annotation will be added to the entry point as well. This may be useful to enable some vendor specific features, or e.g. to enable MTOM to efficiently send binary data to a client.
That also applies for WebService annotation to overwrite values as declared in the WSDL file.
Further, you can also provide your own handler chain binding file. However, handlers and authentication as declared via WebServiceEntryPoint annotation are ignored then.
| Handlers registered via handlerChain must be beans, meaning either annotated with @Bean or @ApplicationScoped. |
| The binding to the concrete endpoint is done via 'endpointInterface' attribute. If a WSDL declares multiple services, create a separate entry point definition for each service to be published. |
| Annotate the Entry Point Definition class with `IgnoreWebServiceEntryPoint' to not generate an entry point for that definition. This is primarily used while developing an entry point, or for documenting purpose. |
Some fields require you to provide a Java class. Such fields are mostly of the annotation type Clazz, which accepts either the concrete Class, or its 'fully qualified name'. Use the latter if the class is not visible from within jaxws module.However, if ever possible specify a Class. Because most classes are looked up via bean manager, this can be achieved with an interface located in 'jaxws' module, but with an implementation in 'server' module.
|
Configure Authentication
The field 'authentication' on WebServiceEntryPoint configures what authentication mechanism to install on the webservice endpoint, and in which RunContext to run authenticated webservice requests. It consists of the IAuthenticationMethod to challenge the client to provide credentials, and the ICredentialVerifier to verify request’s credentials against a data source.
By default, authentication is disabled. If enabled, an AuthenticationHandler is generated and registered in the handler chain as very first handler. The position can be changed via order field on Authentication annotation.
The following properties can be set.
method |
Specifies the authentication method to be used to challenge the client to provide credentials. By default, |
verifier |
Specifies against which data source credentials are to be verified. By default, |
order |
Specifies the position where to register the authentication handler in the handler chain. By default, it is registered as the very first handler. |
principalProducer |
Indicates the principal producer to use to create principals to represent authenticated users. By default, SimplePrincipalProducer is used. |
runContextProducer |
Indicates which RunContext to use to run authenticated webservice requests. By default, |
| If using container based authentication (authentication enforced by the application server), use ContainerBasedAuthenticationMethod as authentication method, and do not configure a credential verifier. |
18.5.4. Example of an Entry Point definition
@WebServiceEntryPoint(
endpointInterface = PingWebServicePortType.class, (1)
entryPointName = "PingWebServiceEntryPoint",
entryPointPackage = "org.eclipse.scout.docs.ws.ping",
serviceName = "PingWebService",
portName = "PingWebServicePort",
handlerChain = {(2)
@Handler(@Clazz(CorrelationIdHandler.class)), (3)
@Handler(value = @Clazz(IPAddressFilter.class), initParams = { (4)
@InitParam(key = "rangeFrom", value = "192.200.0.0"),
@InitParam(key = "rangeTo", value = "192.255.0.0")}),
@Handler(@Clazz(LogHandler.class)), (5)
},
authentication = @Authentication( (6)
order = 2, (7)
method = @Clazz(BasicAuthenticationMethod.class), (8)
verifier = @Clazz(ConfigFileCredentialVerifier.class))) (9)
@MTOM (10)| 1 | References the endpoint interface for which to generate an entry point for. |
| 2 | Declares the handlers to be installed on that entry point. The order is as declared. |
| 3 | Registers the 'CorrelationIdHandler' as the first handler to set a correlation ID onto the current message context. See Section 18.5.6 for more information about state propagation. |
| 4 | Registers the 'IpAddressFilter' as the second handler to filter for IP addresses. Also, this handler is parameterized with 'init params' to configure the valid IP range. |
| 5 | Registers the LogHandler as the third handler to log SOAP messages. |
| 6 | Configures the webservice’s authentication. |
| 7 | Configures the 'AuthHandler' to be put at position 2 (0-based), meaning in between of IpAddressFilter and LogHandler. By default, AuthHandler would be the very first handler in the handler chain. |
| 8 | Configures to use BASIC AUTH as authentication method. |
| 9 | Configures to verify user’s credentials against 'config.properties' file. |
| 10 | Specification of an MTOM annotation to be added to the entry point. |
This configuration generates the following artifacts:
All artifacts are generated into the package 'org.eclipse.scout.docs.ws.ping', as specified by the definition. The entry point itself is generated into 'PingWebServiceEntryPoint.java'. Further, for each handler, a respective handler delegate is generated. That allows handlers to be looked up via bean manager, and to run the handlers on behalf of a RunContext. Also, an AuthHandler is generated to authenticate web requests as configured.
The handler-chain XML file generated looks as following. As specified, the authentication handler is installed as the third handler.
<handler-chains xmlns="http://java.sun.com/xml/ns/javaee">
<handler-chain>
<!-- Executed as 4. handler-->
<handler>
<handler-class>org.eclipse.scout.docs.ws.ping.PingWebServiceEntryPoint_LogHandler</handler-class>
</handler>
</handler-chain>
<handler-chain>
<!-- Executed as 3. handler-->
<handler>
<handler-class>org.eclipse.scout.docs.ws.ping.PingWebServiceEntryPoint_AuthHandler</handler-class>
</handler>
</handler-chain>
<handler-chain>
<!-- Executed as 2. handler-->
<handler>
<handler-class>org.eclipse.scout.docs.ws.ping.PingWebServiceEntryPoint_IPAddressFilter</handler-class>
</handler>
</handler-chain>
<handler-chain>
<!-- Executed as 1. handler-->
<handler>
<handler-class>org.eclipse.scout.docs.ws.ping.PingWebServiceEntryPoint_CorrelationIdHandler</handler-class>
</handler>
</handler-chain>
</handler-chains>The following listing shows the beginning of the entry point generated. As you can see, the handler-chain XML file is referenced via HandlerChain annotation, and the MTOM annotation was added as well.
@WebService(name = "PingWebServicePortType",
targetNamespace = "http://scout.eclipse.org/docs/ws/PingWebService/",
endpointInterface = "org.eclipse.scout.docs.snippets.JaxWsSnippet.PingWebServicePortType",
serviceName = "PingWebService",
portName = "PingWebServicePort")
@MTOM
@HandlerChain(file = "PingWebServiceEntryPoint_handler-chain.xml")
public class PingWebServiceEntryPoint implements PingWebServicePortType {18.5.5. Configure JAX-WS Handlers
See listing for an example of how to configure JAX-WS handlers.
JAX-WS handlers are configured directly on the entry point definition via the array field handlerChain. In turn, JaxWsAnnotationProcessor generates a 'handler XML file' with the handler’s order preserved, and which is registered in entry point via annotation handlerChain.
A handler can be initialized with static 'init parameters', which will be injected into the handler instance. For the injection to work, declare a member of the type Map in the handler class, and annotate it with javax.annotation.Resource annotation.
Because handlers are looked up via bean manager, a handler must be annotated with ApplicationScoped annotation.
If a handler requires to be run in a RunContext, annotate the handler with RunWithRunContext annotation, and optionally specify a RunContextProducer. If the web request is authenticated upon entering the handler, the RunContext is run on behalf of the authenticated user. Otherwise, if not authenticated yet, it is invoked with the Subject as configured in scout.jaxws.provider.user.handler config property.
@ApplicationScoped (1)
@RunWithRunContext (2)
public class IPAddressFilter implements SOAPHandler<SOAPMessageContext> {
@Resource
private Map<String, String> m_initParams; (3)
@Override
public boolean handleMessage(SOAPMessageContext context) {
String rangeForm = m_initParams.get("rangeFrom"); (4)
String rangeTo = m_initParams.get("rangeTo");
// ...
return true;
}
@Override
public boolean handleFault(SOAPMessageContext context) {
return true;
}
@Override
public Set<QName> getHeaders() {
return Collections.emptySet();
}
@Override
public void close(MessageContext context) {
}
}| 1 | Annotate the Handler with ApplicationScoped annotation, so it can be looked up via bean manager |
| 2 | Optionally annotate the Handler with RunWithRunContext annotation, so the handler is invoked in a RunContext |
| 3 | Declare a Map member annotated with Resource annotation to make injection of 'init parameters' work |
| 4 | Access injected 'init parameters' |
18.5.6. Propagate state among Handlers and port type
Sometimes it is useful to share state among handlers, and even with the port type. This can be done via javax.xml.ws.handler.MessageContext. By default, a property put onto message context is only available in the handler chain. To make it available to the port type as well, set its scope to 'APPLICATION' accordingly.
The following listings gives an example of how to propagate state among handlers and port type.
@ApplicationScoped
public class CorrelationIdHandler implements SOAPHandler<SOAPMessageContext> {
@Override
public boolean handleMessage(SOAPMessageContext context) {
context.put("cid", UUID.randomUUID().toString()); (1)
context.setScope("cid", Scope.APPLICATION); (2)
return true;
}
@Override
public boolean handleFault(SOAPMessageContext context) {
return true;
}
@Override
public Set<QName> getHeaders() {
return Collections.emptySet();
}
@Override
public void close(MessageContext context) {
}
}| 1 | Put the 'correlation ID' onto message context. |
| 2 | Set scope to APPLICATION to be accessible in port type. By default, the scope if HANDLER only. |
@ApplicationScoped
public class CorrelationIdLogger implements SOAPHandler<SOAPMessageContext> {
@Override
public boolean handleMessage(SOAPMessageContext context) {
String correlationId = (String) context.get("cid"); (1)
// ...
return true;
}
@Override
public boolean handleFault(SOAPMessageContext context) {
return true;
}
@Override
public void close(MessageContext context) {
}
@Override
public Set<QName> getHeaders() {
return Collections.emptySet();
}
}| 1 | Get the 'correlation ID' from message context. |
@ApplicationScoped
public class CorrelationIdPortType implements PingWebServicePortType {
@Override
public String ping(String ping) {
MessageContext currentMsgCtx = IWebServiceContext.CURRENT.get().getMessageContext(); (1)
String correlationId = (String) currentMsgCtx.get("cid"); (2)
// ...
return ping;
}
}| 1 | Get the current message context via thread local IWebServiceContext |
| 2 | Get the 'correlation ID' from message context. |
18.5.7. JAX-WS Correlation ID Propagation
Scout’s JAX-WS integration already provides complete support for reading a correlation ID from the HTTP header named X-Scout-Correlation-Id of the incoming web service request and propagates it to the RunContext that executes the actual service operation. A new correlation ID is created if the HTTP header is empty or missing.
| The CorrelationIdHandler example above just illustrates the capabilities of a SOAPHandler. |
| You have to implement your own handler if the consumer provides a correlation ID in another header parameter or as part of the request’s payload. |
@WebServiceEntryPoint(
endpointInterface = PingWebServicePortType.class,
entryPointName = "PingWebServiceEntryPoint",
entryPointPackage = "org.eclipse.scout.docs.ws.ping2",
serviceName = "PingWebService",
portName = "PingWebServicePort",
handlerChain = {
@Handler(@Clazz(WsProviderCorrelationIdHandler.class)), (1)
@Handler(@Clazz(LogHandler.class)),
},
authentication = @Authentication(
method = @Clazz(BasicAuthenticationMethod.class),
verifier = @Clazz(ConfigFileCredentialVerifier.class)))| 1 | Add the correlation ID handler at the beginning of the handler chain to ensure that all handlers can use its value (especially the LogHandler has to be added after the correlation ID handler). |
18.5.8. Registration of webservice endpoints
The registration of webservice endpoints depends on the implementor you use, and whether you are running in an EE container with webservice auto discovery enabled.
When running in an EE container, webservice providers are typically found by their presence. In order to be found, such webservice providers must be annotated with WebService annotation, and must have the coordinates 'serviceName' and 'portName' set. Still, most application servers allow for manual registration as well. E.g. if using Oracle WebLogic Server (WLS), endpoints to be published can be registered directly in 'web.xml' as a Servlet. However, this is vendor specific. Refer to the container’s documentation for more information.
If not running in an EE container, the registration is implementor specific. In the following, an example for JAX-WS METRO and Apache CXF is given.
JAX-WS METRO
During startup, JAX-WS METRO looks for the file '/WEB-INF/sun-jaxws.xml', which contains the endpoint definitions.
<jws:endpoints xmlns:jws="http://java.sun.com/xml/ns/jax-ws/ri/runtime" version="2.0">
<!-- PingWebService -->
<jws:endpoint
name="PingService"
implementation="org.eclipse.scout.docs.ws.ping.PingWebServiceEntryPoint"
service="{http://scout.eclipse.org/docs/ws/PingWebService/}PingWebService"
port="{http://scout.eclipse.org/docs/ws/PingWebService/}PingWebServiceSOAP"
url-pattern="/jaxws/PingWebService"/>
</jws:endpoints>Apache CXF
During startup, Apache CXF looks for the config file as specified in 'web.xml' via 'config-location'. See Listing 113 for more information.
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jaxws="http://cxf.apache.org/jaxws"
xsi:schemaLocation=" http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://cxf.apache.org/jaxws http://cxf.apache.org/schemas/jaxws.xsd">
<import resource="classpath:META-INF/cxf/cxf.xml" />
<!-- PingWebService -->
<jaxws:endpoint id="PingWebService"
implementor="org.eclipse.scout.docs.ws.ping.PingWebServiceEntryPoint"
address="/PingWebService" />
</beans>| As the webservice endpoint, specify the fully qualified name to the entry point, and not to the implementing port type. |
|
Depending on the implementor, a HTML page may be provided to see all webservices published. For JAX-WS METRO, enter the URL to a concrete webservice, e.g. http://localhost:8080/jaxws/PingWebService. For Apache CXF, enter the base URL where the webservices are published, e.g. http://localhost:8080/jaxws. |
18.6. Consume a webservice
Communication with a webservice endpoint is done based on the webservice’s port generated by 'wsimport'. Learn more how to generate a webservice stub from a WSDL file.
To interact with a webservice endpoint, create a concrete 'WebServiceClient' class which extends from AbstractWebServiceClient, and specify the endpoint’s coordinates ('service' and 'port') via its bounded type parameters.
public class PingWebServiceClient extends AbstractWebServiceClient<PingWebService, PingWebServicePortType> { (1)
}| 1 | Specify 'service' and 'port' via bounded type parameters |
A WS-Client can be configured with some default values like the endpoint URL, credentials, timeouts and more. However, the configuration can also be set or overwritten later when creating the InvocationContext.
See also Section 18.6.7.
public class PingWebServiceClient1 extends AbstractWebServiceClient<PingWebService, PingWebServicePortType> {
@Override
protected Class<? extends IConfigProperty<String>> getConfiguredEndpointUrlProperty() {
return JaxWsPingEndpointUrlProperty.class; (1)
}
@Override
protected Class<? extends IConfigProperty<String>> getConfiguredUsernameProperty() {
return JaxWsPingUsernameProperty.class; (2)
}
@Override
protected Class<? extends IConfigProperty<String>> getConfiguredPasswordProperty() {
return JaxWsPingPasswordProperty.class; (2)
}
@Override
protected Class<? extends IConfigProperty<Integer>> getConfiguredConnectTimeoutProperty() {
return JaxWsPingConnectTimeoutProperty.class; (3)
}
@Override
protected Class<? extends IConfigProperty<Integer>> getConfiguredReadTimeoutProperty() {
return JaxWsPingReadTimeoutProperty.class; (3)
}
}| 1 | Specifies the endpoint URL |
| 2 | Specifies credentials |
| 3 | Specifies timeouts |
18.6.1. Invoke a webservice
A webservice operation is invoked on behalf of an invocation context, which is associated with a dedicated port, and which specifies the data to be included in the web request. Upon a webservice call, the invocation context should be discarded.
PingWebServicePortType port = BEANS.get(PingWebServiceClient.class).newInvocationContext().getPort(); (1)
port.ping("Hello world"); (2)| 1 | Obtain a new invocation context and port via WS-Client |
| 2 | Invoke the webservice operation |
Invoking newInvocationContext() returns a new context and port instance. The context returned inherits all properties as configured for the WS-Client (endpoint URL, credentials, timeouts, …), but which can be overwritten for the scope of this context.
The following listing illustrates how to set/overwrite properties.
final InvocationContext<PingWebServicePortType> context = BEANS.get(PingWebServiceClient.class).newInvocationContext();
PingWebServicePortType port = context
.withUsername("test-user") (1)
.withPassword("secret")
.withConnectTimeout(10, TimeUnit.SECONDS) (2)
.withoutReadTimeout() (3)
.withHttpRequestHeader("X-ENV", "integration") (4)
.getPort();
port.ping("Hello world"); (5)| 1 | Set the credentials |
| 2 | Change the connect timeout to 10s |
| 3 | Unset the read timeout |
| 4 | Add a HTTP request header |
| 5 | Invoke the webservice operation |
The WS-Client provides port instances via a preemptive port cache. This cache improves performance because port creation may be an expensive operation due to WSDL/schema validation. The cache is based on a 'corePoolSize', meaning that that number of ports is created on a preemptively basis. If more ports than that number are required, they are created on demand, and additionally added to the cache until expired, which is useful at a high load.
| The JAX-WS specification does not specify thread safety of a port instance. Therefore, a port should not be used concurrently among threads. Further, JAX-WS API does not support to reset the Port’s request and response context, which is why a port should only be used for a single webservice call. |
18.6.2. Cancel a webservice request
The WS-Client supports for cancellation of webservice requests. Internally, every web request is run in another thread, which the calling thread waits for to complete. Upon cancellation, that other thread is interrupted, and the calling thread released with a WebServiceRequestCancelledException. However, depending on the JAX-WS implementor, the web request may still be running, because JAX-WS API does not support the cancellation of a web request.
18.6.3. Get information about the last web request
The invocation context allows you to access HTTP status code and HTTP headers of the last web request.
final InvocationContext<PingWebServicePortType> context = BEANS.get(PingWebServiceClient.class).newInvocationContext();
String pingResult = context.getPort().ping("Hello world");
// Get HTTP status code
int httpStatusCode = context.getHttpStatusCode();
// Get HTTP response header
List<String> httpResponseHeader = context.getHttpResponseHeader("X-CUSTOM-HEADER");18.6.4. Propagate state to Handlers
An invocation context can be associated with request context properties, which are propagated to handlers and JAX-WS implementor.
BEANS.get(PingWebServiceClient.class).newInvocationContext()
.withRequestContextProperty("cid", UUID.randomUUID().toString()) (1)
.getPort().ping("Hello world"); (2)| 1 | Propagate the correlation ID |
| 2 | Invoke the web operation |
Learn more how to access context properties from within a handler in Listing 126.
18.6.5. Install handlers and provide credentials for authentication
To install a handler, overwrite execInstallHandlers and add the handler to the given List. The handlers are invoked in the order as added to the handler-chain. By default, there is no handler installed.
The method execInstallHandlers is invoked upon preemptive creation of the port. Consequently, you cannot do any assumption about the calling thread.
If a handler requires to run in another RunContext than the calling context, annotate it with RunWithRunContext annotation, e.g. to start a new transaction to log into database.
If the endpoint requires to authenticate requests, an authentication handler is typically added to the list, e.g. BasicAuthenticationHandler for 'Basic authentication', or WsseUsernameTokenAuthenticationHandler for 'Message Level WS-Security authentication', or some other handler to provide credentials.
public class PingWebServiceClient2 extends AbstractWebServiceClient<PingWebService, PingWebServicePortType> {
@Override
protected void execInstallHandlers(List<javax.xml.ws.handler.Handler<?>> handlerChain) {
handlerChain.add(new BasicAuthenticationHandler());
handlerChain.add(BEANS.get(LogHandler.class));
}
}
The credentials as provided via InvocationContext can be accessed via request context with the property InvocationContext.PROP_USERNAME and InvocationContext.PROP_PASSWORD.
|
18.6.6. JAX-WS Client Correlation ID Propagation
The current context’s correlation ID can be forwarded to the consumed web service. Scout provides a handler that sets the X-Scout-Correlation-Id HTTP header on the outgoing request.
public class PingWebServiceClient3 extends AbstractWebServiceClient<PingWebService, PingWebServicePortType> {
@Override
protected void execInstallHandlers(List<javax.xml.ws.handler.Handler<?>> handlerChain) {
handlerChain.add(new BasicAuthenticationHandler());
handlerChain.add(BEANS.get(LogHandler.class));
handlerChain.add(BEANS.get(WsConsumerCorrelationIdHandler.class)); (1)
}
}| 1 | The handler can be at any position in the handler chain. |
18.6.7. Default configuration of WS-Clients
The following properties can be set globally for all WS-Clients. However, a WS-Client can overwrite any of this values.
| property | description | default value |
|---|---|---|
scout.jaxws.consumer.portCache.enabled |
To indicate whether to use a preemptive port cache for WS-Clients. |
true |
scout.jaxws.consumer.portCache.corePoolSize |
Number of ports to be preemptively cached to speed up webservice calls. |
10 |
scout.jaxws.consumer.portCache.ttl |
Maximum time in seconds to retain ports in the cache if the 'corePoolSize' is exceeded. That typically occurs at high load, or if 'corePoolSize' is undersized. |
15 minutes |
scout.jaxws.consumer.connectTimeout |
Connect timeout in milliseconds to abort a webservice request, if establishment of the HTTP connection takes longer than this timeout. A timeout of null means an infinite timeout. |
infinite |
scout.jaxws.consumer.readTimeout |
Read timeout in milliseconds to abort a webservice request, if it takes longer than this timeout for data to be available for read. A timeout of null means an infinite timeout. |
infinite |
18.7. XML adapters to work with java.util.Date and java.util.Calendar
Scout ships with some XML adapters to not have to work with XMLGregorianCalendar, but with java.util.Date instead.
It is recommended to configure your global binding file accordingly. See Listing 118 for an example.
See the adapter’s JavaDoc for more detailed information.
| adapter | description |
|---|---|
UtcDateAdapter |
Use this adapter to work with UTC xsd:dates. A UTC date is also known as 'zulu' date, and has 'GMT+-00:00'. Unlike |
UtcTimeAdapter |
Use this adapter to work with UTC xsd:times. A UTC time is also known as 'zulu' time, and has 'GMT+-00:00'. Unlike |
UtcDateTimeAdapter |
Use this adapter to work with UTC xsd:dateTimes. A UTC time is also known as 'zulu' time, and has 'GMT+-00:00'. This adapter converts xsd:dateTime into UTC milliseconds, by respecting the timezone as provided. If the timezone is missing, the date is interpreted as UTC-time, and not local to the default JVM timezone. To convert a |
| adapter | description |
|---|---|
CalendarDateAdapter |
Use this adapter to work with |
CalendarTimeAdapter |
Use this adapter to work with |
CalendarDateTimeAdapter |
Adapter to convert a xsd:dateTime to a |
| adapter | description |
|---|---|
DefaultTimezoneDateAdapter |
Use this adapter to work with xsd:dates in the default timezone of the Java Virtual Machine. Depending on the JVM installation, the timezone may differ: 'GMT+-XX:XX'. Unlike |
DefaultTimezoneTimeAdapter |
Use this adapter to work with xsd:times in the default timezone of the Java Virtual Machine. Depending on the JVM installation, the timezone may differ: 'GMT+-XX:XX'. Unlike DefaultTimezoneDateTimeAdapter, this adapter sets year, month and day to the epoch, which is defined as 1970-01-01 in UTC. |
DefaultTimezoneDateTimeAdapter |
Use this adapter to work with xsd:dateTimes in the default timezone of the Java Virtual Machine. Depending on the JVM installation, the timezone may differ: 'GMT+-XX:XX'. |
18.8. JAX-WS Appendix
18.8.1. PingWebService.wsdl
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<wsdl:definitions name="PingWebService"
targetNamespace="http://scout.eclipse.org/docs/ws/PingWebService/"
xmlns:tns="http://scout.eclipse.org/docs/ws/PingWebService/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<wsdl:types>
<xsd:schema targetNamespace="http://scout.eclipse.org/docs/ws/PingWebService/">
<xsd:element name="pingRequest" type="xsd:string"/>
<xsd:element name="pingResponse" type="xsd:string"/>
</xsd:schema>
</wsdl:types>
<wsdl:message name="pingRequest">
<wsdl:part element="tns:pingRequest" name="ping" />
</wsdl:message>
<wsdl:message name="pingResponse">
<wsdl:part element="tns:pingResponse" name="parameters" />
</wsdl:message>
<wsdl:portType name="PingWebServicePortType">
<wsdl:operation name="ping">
<wsdl:input message="tns:pingRequest" />
<wsdl:output message="tns:pingResponse" />
</wsdl:operation>
</wsdl:portType>
<wsdl:binding name="PingWebServiceSOAP" type="tns:PingWebServicePortType">
<soap:binding style="document"
transport="http://schemas.xmlsoap.org/soap/http" />
<wsdl:operation name="ping">
<soap:operation soapAction="http://scout.eclipse.org/docs/ws/PingWebService/ping" />
<wsdl:input>
<soap:body use="literal" />
</wsdl:input>
<wsdl:output>
<soap:body use="literal" />
</wsdl:output>
</wsdl:operation>
</wsdl:binding>
<wsdl:service name="PingWebService">
<wsdl:port binding="tns:PingWebServiceSOAP" name="PingWebServiceSOAP">
<soap:address location="http://scout.eclipse.org/docs/ws/PingWebService/" />
</wsdl:port>
</wsdl:service>
</wsdl:definitions>18.8.2. PingWebServicePortType.java
@FunctionalInterface
@WebService(name = "PingWebServicePortType", targetNamespace = "http://scout.eclipse.org/docs/ws/PingWebService/")
@SOAPBinding(parameterStyle = ParameterStyle.BARE)
public interface PingWebServicePortType {
@WebMethod(action = "http://scout.eclipse.org/docs/ws/PingWebService/ping")
@WebResult(name = "pingResponse", targetNamespace = "http://scout.eclipse.org/docs/ws/PingWebService/", partName = "parameters")
String ping(@WebParam(name = "pingRequest", targetNamespace = "http://scout.eclipse.org/docs/ws/PingWebService/", partName = "ping") String ping);
}18.8.3. PingWebServicePortTypeEntryPoint.java
@Generated(value = "org.eclipse.scout.jaxws.apt.JaxWsAnnotationProcessor", date = "2016-01-25T14:22:58:583+0100", comments = "EntryPoint to run webservice requests on behalf of a RunContext")
@WebService(name = "PingWebServicePortType", targetNamespace = "http://scout.eclipse.org/docs/ws/PingWebService/", endpointInterface = "org.eclipse.scout.docs.ws.pingwebservice.PingWebServicePortType")
public class PingWebServicePortTypeEntryPoint implements org.eclipse.scout.docs.ws.pingwebservice.PingWebServicePortType {
@Resource
protected WebServiceContext m_webServiceContext;
@Override
public String ping(final String ping) {
try {
return lookupRunContext().call(new Callable<String>() {
@Override
public final String call() throws Exception {
return BEANS.get(PingWebServicePortType.class).ping(ping);
}
}, DefaultExceptionTranslator.class);
}
catch (Exception e) {
throw handleUndeclaredFault(e);
}
}
protected RuntimeException handleUndeclaredFault(final Exception e) {
throw BEANS.get(JaxWsUndeclaredExceptionTranslator.class).translate(e);
}
protected RunContext lookupRunContext() {
return BEANS.get(JaxWsRunContextLookup.class).lookup(m_webServiceContext);
}
}18.8.4. PingWebServicePortTypeBean.java
@ApplicationScoped
public class PingWebServicePortTypeBean implements PingWebServicePortType {
@Override
public String ping(String ping) {
return "ping: " + ping;
}
}18.8.5. .settings/org.eclipse.jdt.core.prefs file to enable APT in Eclipse IDE
...
org.eclipse.jdt.core.compiler.processAnnotations=enabled
...18.8.6. .settings/org.eclipse.jdt.apt.core.prefs file to enable APT in Eclipse IDE
org.eclipse.jdt.apt.aptEnabled=true
org.eclipse.jdt.apt.genSrcDir=target/generated-sources/annotations
org.eclipse.jdt.apt.processorOptions/consoleLog=true
org.eclipse.jdt.apt.reconcileEnabled=true18.8.7. .factorypath file to enable APT in Eclipse IDE
<!-- Replace 'XXX-VERSION-XXX' by the respective Scout RT version -->
<factorypath>
<factorypathentry kind="VARJAR" id="M2_REPO/org/eclipse/scout/rt/org.eclipse.scout.jaxws.apt/XXX-VERSION-XXX/org.eclipse.scout.jaxws.apt-XXX-VERSION-XXX.jar" enabled="true" runInBatchMode="false"/>
<factorypathentry kind="VARJAR" id="M2_REPO/com/unquietcode/tools/jcodemodel/codemodel/1.0.3/codemodel-1.0.3.jar" enabled="true" runInBatchMode="false"/>
<factorypathentry kind="VARJAR" id="M2_REPO/org/eclipse/scout/rt/org.eclipse.scout.rt.platform/XXX-VERSION-XXX/org.eclipse.scout.rt.platform-XXX-VERSION-XXX.jar" enabled="true" runInBatchMode="false"/>
<factorypathentry kind="VARJAR" id="M2_REPO/org/eclipse/scout/rt/org.eclipse.scout.rt.server.jaxws/XXX-VERSION-XXX/org.eclipse.scout.rt.server.jaxws-XXX-VERSION-XXX.jar" enabled="true" runInBatchMode="false"/>
<factorypathentry kind="VARJAR" id="M2_REPO/javax/servlet/javax.servlet-api/3.1.0/javax.servlet-api-3.1.0.jar" enabled="true" runInBatchMode="false"/>
<factorypathentry kind="VARJAR" id="M2_REPO/org/slf4j/slf4j-api/1.7.12/slf4j-api-1.7.12.jar" enabled="true" runInBatchMode="false"/>
</factorypath>18.8.8. Authentication Method
The authentication method specifies the protocol to challenge the webservice client to provide credentials.
Scout provides an implementation for BASIC and WSSE_UsernameToken. You can implement your own authentication method by implementing IAuthenticationMethod interface.
BasicAuthenticationMethod
Authentication method to apply Basic Access Authentication. This requires requests to provide a valid user name and password to access content. User’s credentials are transported in HTTP headers. Basic authentication also works across firewalls and proxy servers.
However, the disadvantage of Basic authentication is that it transmits unencrypted base64-encoded passwords across the network. Therefore, you only should use this authentication when you know that the connection between the client and the server is secure. The connection should be established either over a dedicated line or by using Secure Sockets Layer (SSL) encryption and Transport Layer Security (TLS).
WsseUsernameTokenMethod
Authentication method to apply Message Level WS-Security with UsernameToken Authentication. This requires requests to provide a valid user name and password to access content. User’s credentials are included in SOAP message headers.
However, the disadvantage of WSSE UsernameToken Authentication is that it transmits unencrypted passwords across the network. Therefore, you only should use this authentication when you know that the connection between the client and the server is secure. The connection should be established either over a dedicated line or by using Secure Sockets Layer (SSL) encryption and Transport Layer Security (TLS).
18.8.9. Credential Verifier
Verifies user’s credentials against a data source like database, config.properties, Active Directory, or others.
Scout provides an implementation for verification against users in config.properties. You can implement your own verifier by implementing ICredentialVerifier interface.
If you require to run in a specific RunContext like a transaction for user’s verification, annotate the verifier with RunWithRunContext annotation, and specify a RunContextProducer accordingly.
|
ConfigFileCredentialVerifier
Credential verifier against credentials configured in config.properties file.
By default, this verifier expects the passwords in 'config.properties' to be a hash produced with SHA-512 algorithm. To support you in password hash generation, ConfigFileCredentialVerifier provides a static Java main method.
Credentials are loaded from property scout.auth.credentials. Multiple credentials are separated with the semicolon, username and password with the colon. If using hashed passwords (by default), the password’s salt and hash are separated with the dot.
To work with plaintext passwords, set the property scout.auth.credentialsPlaintext to true.
Example of hashed passwords: scott:SALT.PASSWORD-HASH;jack:SALT.PASSWORD-HASH;john:SALT.PASSWORD-HASH
Example of plaintext passwords: scott:*;jack:;john:*
19. SmtpHelper
The org.eclipse.scout.rt.mail.smtp.SmtpHelper is an @ApplicationScoped Bean that provides means of sending emails described by javax.mail.internet.MimeMessage objects via SMTP.
The SMTP connection can either be provided as a org.eclipse.scout.rt.mail.smtp.SmtpServerConfig object containing all the required connection parameters or as an already created javax.mail.Session object.
The SmtpHelper also supports pooling of SMTP connections as described in the section Section 19.4.
19.1. SmtpServerConfig
The org.eclipse.scout.rt.mail.smtp.SmtpServerConfig class allows to specify details of an SMTP connection to be made. It supports the following properties:
| Property | Description | Example |
|---|---|---|
host |
The hostname or ip address of the SMTP server to use. |
|
port |
The TCP port the SMTP server listens on. |
E.g. 25 or 465. |
username |
The username to use for authentication. |
- |
password |
The password to use for authentication. |
- |
useAuthentication |
Whether to use authentication or not. This setting is only effective, if a username has been provided. |
- |
useSmtps |
If true, the protocol will be 'smtps', else the protocol will be 'smtp'. |
- |
useStartTls |
If true, STARTTLS will be used to create the connection to the SMTP server. |
- |
sslProtocols |
Limits the SSL protocols to support when connecting to the SMTP server. The value is a space separated list of protocol names returned by the |
E.g. "TLSv1.1 TLSv1.2" |
additionalSessionProperties |
Can be used to specify any other property for the |
"mail.smtp.socketFactory.class": "com.example.net.SocketFactory" |
poolSize |
Allows to specify the size of the connection pool for this |
4 |
maxMessagesPerConnection |
Allows to specify the max number of messages to be sent per connection when using connection pooling ( |
20 |
Listing 135 demonstrates how to use the SmtpServerConfig class.
org.eclipse.scout.rt.mail.smtp.SmtpServerConfig@SuppressWarnings("unused")
SmtpServerConfig smtpServerConfig = BEANS.get(SmtpServerConfig.class)
.withHost("mail.example.com")
.withPort(465)
.withUsername("smtpuser")
.withPassword("smtpuserpwd")
.withUseAuthentication(true)
.withUseSmtps(true)
.withUseStartTls(true);19.2. Sending messages
Messages can be sent using the sendMessage Methods of the SmtpHelper class. In Order to prepare the message to be sent, Scout provides a number of classes and helpers:
| Class | Description |
|---|---|
|
Encapsulates all the information about a single mail message (sender, recipient, carbon-copy recipients, subject, body, attachments, etc.). |
|
Defines email address and name of a mail participant. A participant can be a recipient, a carbon-copy recipient, a blind-carbon-copy recipient, the sender and a replyTo contact. |
|
Contains information about an email attachment. |
|
Provides various helper methods around email bodies, attachments, etc. |
Listing 136 shows the usage of the mentioned classes Scout provides in order to create a MimeMessage object.
org.eclipse.scout.rt.mail.CharsetSafeMimeMessage object// create BinaryResource for an attachment.
BinaryResource screenshotResource = BinaryResources.create()
.withFilename("screenshot.jpg")
.withContentType("image/jpeg")
.withContent(bytes)
.build();
// wrap BinaryResource in MailAttachment
MailAttachment screenshotAttachment = new MailAttachment(screenshotResource);
// prepare Scout MailMessage
MailMessage mailMessage = BEANS.get(MailMessage.class)
.withSender(BEANS.get(MailParticipant.class).withName("sender").withEmail("me@example.com"))
.addToRecipient(BEANS.get(MailParticipant.class).withName("recipient").withEmail("somebody@example.com"))
.withAttachment(screenshotAttachment)
.withSubject("Screenshot")
.withBodyPlainText("Dear recipient,\n\nPlease have a look at my screenshot!\n\nRegards,\nsender");
// convert MailMessage to MimeMessage
CharsetSafeMimeMessage mimeMessage = BEANS.get(MailHelper.class).createMimeMessage(mailMessage);In order to send the message you can either use a org.eclipse.scout.rt.mail.smtp.SmtpServerConfig object or an existing javax.mail.Session object as demonstrated in Listing 137 and Listing 138.
org.eclipse.scout.rt.mail.smtp.SmtpServerConfig object.BEANS.get(SmtpHelper.class).sendMessage(smtpServerConfig, mimeMessage);javax.mail.Session object.// The password has to be provided additionally as it is not stored in the session object.
BEANS.get(SmtpHelper.class).sendMessage(session, password, mimeMessage);19.3. SmtpHelper Configuration
The SmtpHelper provides some config properties that allow to modify certain behaviour.
| Key | Description | Example |
|---|---|---|
scout.smtp.debugReceiverEmail |
If this property is set, the |
|
scout.smtp.connectionTimeout |
Specifies the connection timeout for SMTP connections in milliseconds. Default is 60 seconds. |
30000 |
scout.smtp.readTimeout |
Specifies the read timeout for SMTP connections in milliseconds. Default is 60 seconds. |
30000 |
19.4. Connection Pooling
Normally, the SmtpHelper opens a new connection for every email which is then closed after the email has been sent.
If you want to send a lot of emails, this behaviour is rather inefficient as opening a new SMTP connection takes a long time compared to sending the email especially when using encrypted connections.
To mitigate this overhead, the SmtpHelper supports pooling of SMTP connections which is activated using the poolSize property of SmtpServerConfig objects.
If you set the pool size property to a value > 0, the SmtpHelper will create parallel connections up to the specified number.
This means, that connection pooling is not possible when you use the sendMessage method accepting an already prepared javax.mail.Session object.
Pooling in this context means the following:
-
All SMTP server connections sharing the same
SmtpServerConfigobject (by same meaning being equal according toSmtpServerConfig.equals()) belong to the same pool -
For each different
SmtpServerConfigobject (again usingSmtpServerConfig.equals()) up to the specified pool size connections are created -
Connections are not immediately closed after an email has been sent, instead they are returned to the pool as idle connections.
-
Before creating new connections, idle connections are reused.
-
When trying to send an email while all the SMTP connections are currently in use and the pool size has already been reached, the calling thread is blocked until a connection is returned as idle to the pool or as soon as the wait-for-connection-timeout has exceeded.
-
As long as connections are open, a background job monitors their state and closes idle and old connections.
19.5. SmtpConnectionPool Configuration
The following config properties allow to modify the behavior of the connection pool implementation at the global level:
| key | Description | Example |
|---|---|---|
scout.smtp.pool.maxIdleTime |
Specifies how long in seconds a connection can be idle before it is closed by the background cleanup job. Default is 60 seconds. |
30 |
scout.smtp.pool.maxConnectionLifetime |
Specifies how long in seconds a connection can be open before it is closed. This is to prevent connections from being open forever when sending emails on a regular basis. Default is 1h. |
7200 |
scout.smtp.pool.waitForConnectionTimeout |
Max. wait time for SMTP connection in seconds. If the value is 0, callers will wait infinitely long for SMTP connections. Default is 300 seconds. |
100 |
20. Scout JS
Scout JS is the technology used by Scout to render your application. The client model defined using Java code is sent to the browser where Scout JS comes into action by taking that model and generating HTML elements.
But Scout JS is a lot more: it can be used to create applications without having a Java based client model at all. You can find out more about Scout JS and its concepts in the Technical Guide for Scout JS.
21. How-Tos
This chapter provides various small technical guides to very specific Scout subjects.
21.1. SmartField: how to apply colors and styles from a lookup-row
When a user selects a lookup-row from the proposal chooser in Scout versions ⇐ 6.0, the properties foregroundColor, backgroundColor, font and tooltipText have been automatically copied from the lookup-row to the field. In some cases this was exactly what a specific application needed, but in other cases it was hard to implement a specific behavior without overriding internal methods from the SmartField. For instance it was not possible to have a lookup-row with background-color red in the proposal-chooser and at the same time avoid the background-color of the field changing to red, when that row was being selected.
Since that automatic behavior didn’t fit every business requirement, we removed it completely. This means a programmer must now implement specific code to read properties from the lookup-row and set them on the field. The following example is from the Scout widgets app. It changes the background-color of the field.
@Override
protected void execChangedValue() {
updateFieldBackgroundColor();
}
/**
* Sets the color of the field to the color of the selected lookup row.
*/
protected void updateFieldBackgroundColor() {
ILookupRow<?> lookupRow = getLookupRow();
String bgColor = lookupRow == null ? null : lookupRow.getBackgroundColor();
setBackgroundColor(bgColor);
}Since Scout 8.0 the property cssClass from the lookup-row is automatically applied to the .form-field DIV. This gives the programmer the flexibility to style either both, lookup-row and field, or only the lookup-row in the proposal-chooser via CSS/LESS.
Here’s a LESS example from the Scout widget app that sets the background-color of lookup-row and field. It is used for the EventTypeCodeType which defines 3 codes with the CSS classes public, private and external:
.form-field.public > .field, .table-row.public {
background-color: @palette-green-0;
}
.form-field.private > .field, .table-row.private {
background-color: @palette-orange-1;
}
.form-field.external > .field, .table-row.external {
background-color: @palette-gray-3;
}Conclusion: older Scout apps that rely on the automatic behavior for the properties mentioned above, should use CSS classes instead of the properties back-/foregroundColor or font. If that’s not possible you should implement logic as shown in the example above where required, possibly moving that code in a class that extends AbstractSmartField, if the same code is required in multiple places.
Appendix A: Licence and Copyright
This appendix first provides a summary of the Creative Commons (CC-BY) licence used for this book. The licence is followed by the complete list of the contributing individuals, and the full licence text.
A.1. Licence Summary
This work is licensed under the Creative Commons Attribution License. To view a copy of this license, visit https://creativecommons.org/licenses/by/3.0/ or send a letter to Creative Commons, 559 Nathan Abbott Way, Stanford, California 94305, USA.
A summary of the license is given below, followed by the full legal text.
You are free:
-
to Share ---to copy, distribute and transmit the work
-
to Remix---to adapt the work
-
to make commercial use of the work
Under the following conditions:
Attribution ---You must attribute the work in the manner specified by the author or licensor (but not in any way that suggests that they endorse you or your use of the work).
With the understanding that:
Waiver ---Any of the above conditions can be waived if you get permission from the copyright holder.
Public Domain ---Where the work or any of its elements is in the public domain under applicable law, that status is in no way affected by the license.
Other Rights ---In no way are any of the following rights affected by the license:
-
Your fair dealing or fair use rights, or other applicable copyright exceptions and limitations;
-
The author’s moral rights;
-
Rights other persons may have either in the work itself or in how the work is used, such as publicity or privacy rights.
Notice ---For any reuse or distribution, you must make clear to others the license terms of this work. The best way to do this is with a link to https://creativecommons.org/licenses/by/3.0/.
A.2. Contributing Individuals
Copyright (c) 2012-2014.
In the text below, all contributing individuals are listed in alphabetical order by name. For contributions in the form of GitHub pull requests, the name should match the one provided in the corresponding public profile.
Bresson Jeremie, Fihlon Marcus, Nick Matthias, Schroeder Alex, Zimmermann Matthias
A.3. Full Licence Text
The full licence text is available online at http://creativecommons.org/licenses/by/3.0/legalcode
| Do you want to improve this document? Have a look at the sources on GitHub. |